
面试笔记整理
注意力
MHA、MQA、GQA 到底有什么区别?一期动画彻底讲透
MHA (Muti-head Attention)
MHA 核心思想是将输入映射到多个子空间,分别计算注意力权重并聚合结果,从而增强模型对复杂模式的捕捉能力。
MQA (Muti-Query Attention)
MQA 核心思想是共享键(Key)和值(Value)的投影参数,仅对查询(Query)使用独立的头参数。
GQA (Grouped-Query Attention)
GQA 是对多头注意力(MHA)和多头潜在注意力(MQA)的折中优化方案。
MLA(Multi-head Latent Attention)
MLA 核心思想是通过低秩投影压缩查询(Q)、键(K)、值(V)的维度,并在注意力计算中解耦内容与位置信息,从而减少计算复杂度,同时保留长距离依赖建模能力。
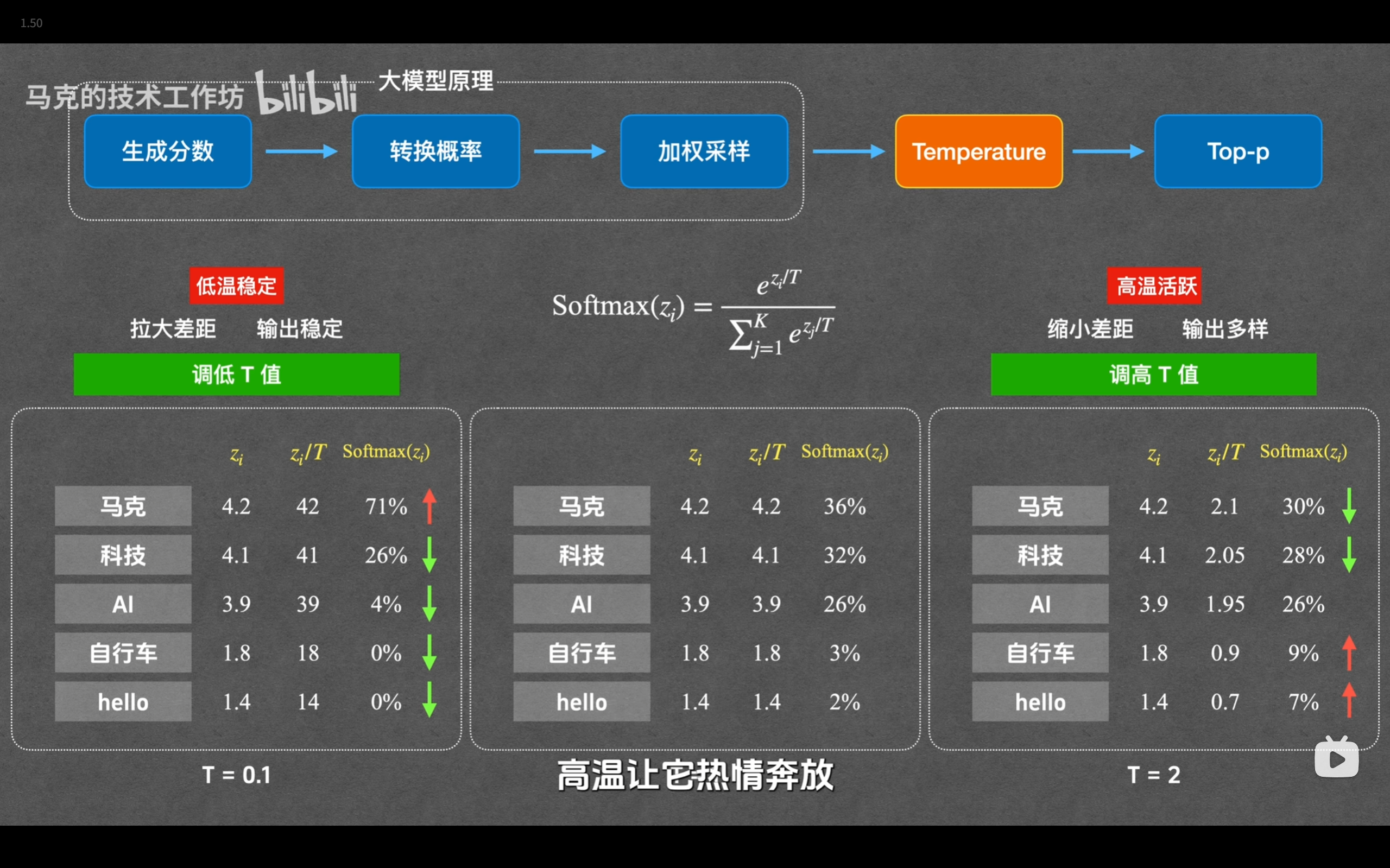
Temperature & Top-p
Temperature & Top-p:掌控大模型的创造力开关
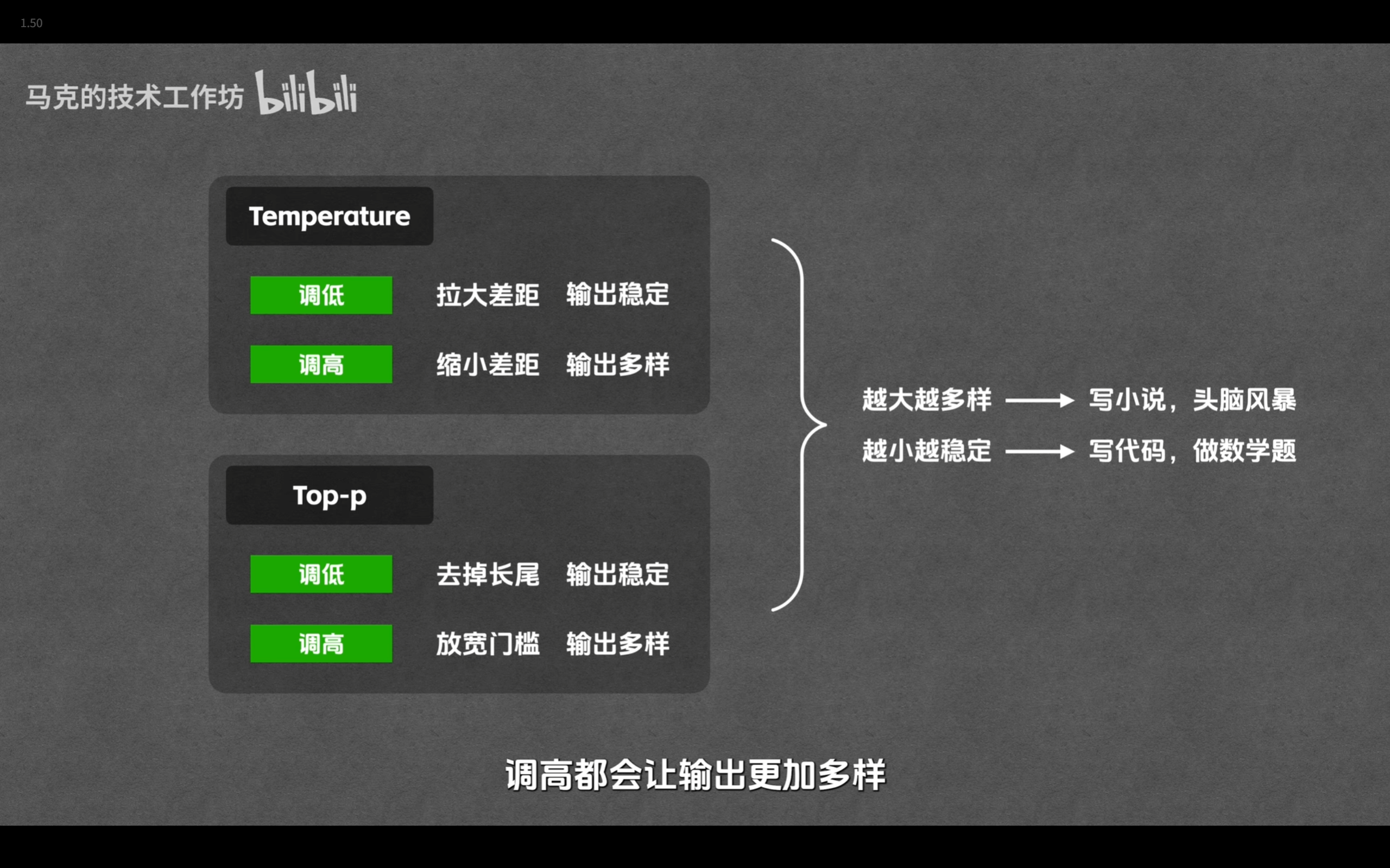
低温稳定、高温活跃
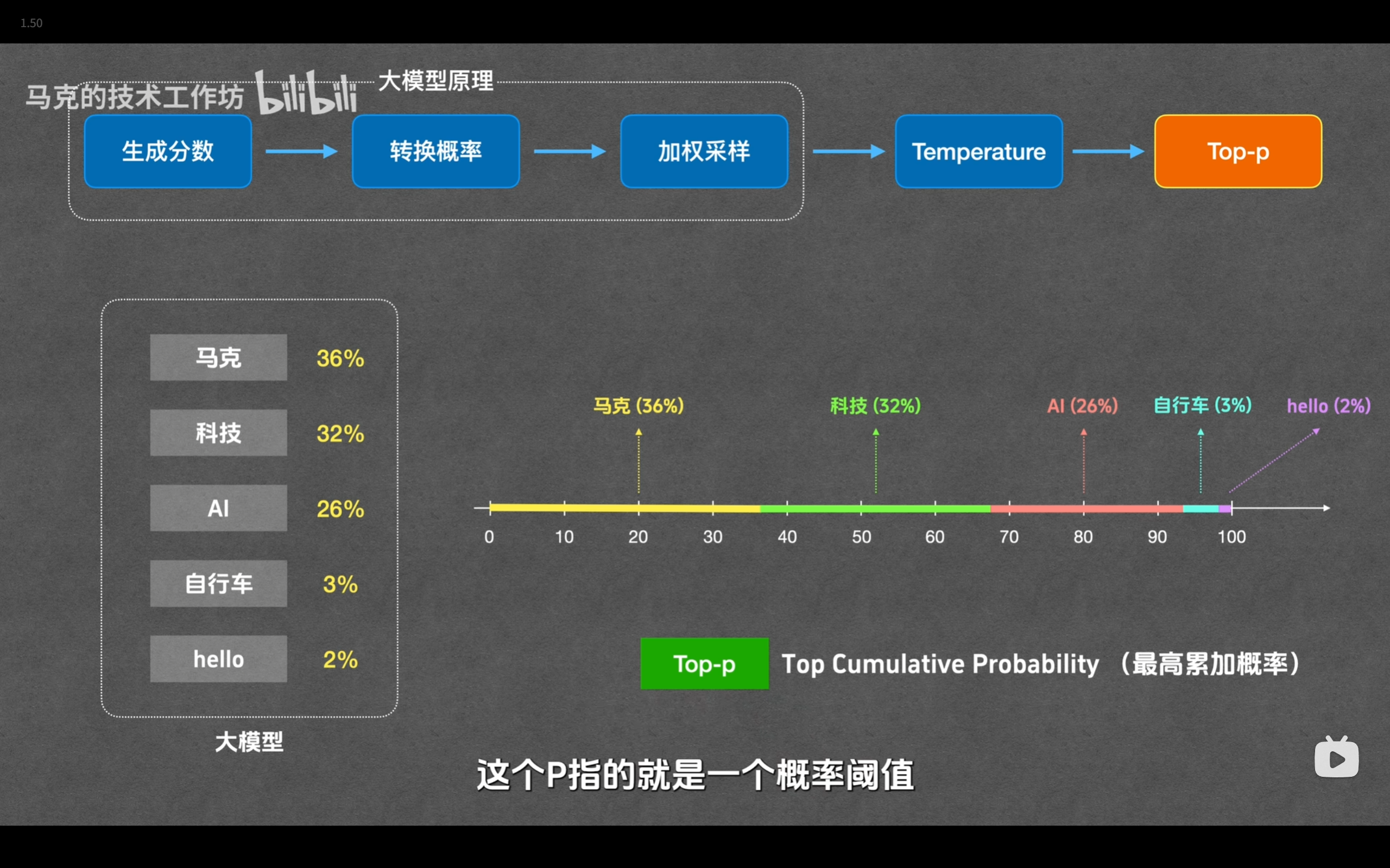
top-p 采样是一种动态截断概率分布的方法。它会将候选词按概率从高到低排序,并累加它们的概率,当累加值达到设定的阈值 $p$(例如 0.9)时,截断后面的词,然后在这个高概率候选集合(Nucleus)中进行随机采样。
Lora & QLora


位置编码(正余弦位置编码 | RoPE旋转位置编码)




分词器(Tokenizer)
按“词”切问题是:
- 词表会非常大
- 会有大量 OOV(未登录词)
- 拼写变化、新词、人名、代码变量名都很麻烦
按“字符”切问题是:
- 序列太长
- token 语义太弱
- 训练和推理成本高
所以现代方法通常取中间路线:使用子词(subword)作为基本单位。
- BPE(Byte Pair Encoding)
迭代重复以下步骤:
- 统计当前语料中所有相邻符号对出现次数
- 找到频率最高的 pair
- 把这个 pair 合并为一个新 token
- 更新语料表示
- 记录这次 merge 规则
WordPiece
WordPiece 训练时,也从较小单位开始,例如字符。但它在选择合并对象时,不只是看频率,而是看一种类似下面的收益:合并后是否能提高训练语料的似然 / 概率
虽然具体实现细节可能因系统不同而略有差别,但核心思想是:选那个最能提升整体分词建模质量的候选子词。Unigram
Unigram 假设:
一个词或句子可以被切分成若干 token,而每个 token 有自己的概率。
一个切分方案的概率,可以由各 token 的概率乘起来(或 log 概率相加)得到。
模型的目标是:找到一个 token 集合,使得训练语料在这个 token 集合下的总体概率最大。
这也是为什么它叫 Unigram Language Model。BBPE(Byte-level Byte Pair Encoding)
先把文本表示成字节序列,再在字节层面上执行 BPE。注意它和普通 BPE 的核心区别不在“是否做 BPE”,而在于:- 普通 BPE 的基础单位通常是字符
- BBPE 的基础单位是字节(byte)
Layer Normalization(LN) & BN & RMSNorm
Batch Normalization 最早提出,在卷积神经网络(CNN)中取得了巨大成功。它的核心思想是:对同一个特征(Channel)在整个 Batch 的所有样本上进行归一化。
为了解决 BN 在小 Batch Size 和变长序列上的缺陷,Layer Normalization 被提出,并成为了 Transformer 架构的标配。它的核心思想是:对同一个样本的所有特征进行归一化。
在 Layer Normalization 中,均值中心化(减去均值 $\mu$)这一步对模型性能的贡献微乎其微,真正起作用的是缩放(除以方差)。RMSNorm 放弃了计算均值,假设均值始终为 0,直接使用**均方根(Root Mean Square)来进行归一化。
奇异值分解
奇异值分解(Singular Value Decomposition,简称 SVD)被誉为线性代数中的“瑞士军刀”。无论是数据压缩、降维(如 PCA),还是推荐系统和自然语言处理,SVD 都有着极其重要的应用。
一、 SVD 的数学定义:拆解矩阵
在数学上,SVD 告诉我们一个极其优雅的结论:任何一个矩阵都可以被分解为三个结构简单的矩阵的乘积。
假设我们有一个大小为 $m \times n$ 的实数矩阵 $A$(不必是方阵),SVD 可以将其分解为:
我们来逐一拆解这三个部分:
$V^T$ (右奇异矩阵的转置): 这是一个 $n \times n$ 的正交矩阵(Orthogonal Matrix)。正交矩阵有一个非常好的性质:它的行向量和列向量彼此垂直且长度为 1。
$\Sigma$ (奇异值矩阵): 这是一个 $m \times n$ 的对角矩阵(Diagonal Matrix)。除了对角线上的元素外,其他全为 0。对角线上的值被称为奇异值(Singular Values),通常记为 $\sigma_1, \sigma_2, \dots$,并且按照从大到小的顺序排列($\sigma_1 \ge \sigma_2 \ge \dots \ge 0$)。奇异值代表了数据在对应方向上的“重要程度”或“能量”。
$U$ (左奇异矩阵): 这是一个 $m \times m$ 的正交矩阵。
二、 SVD 的几何直觉:旋转与拉伸
一堆数学符号可能有些抽象。如果把矩阵看作是对空间的一种线性变换(比如把一个向量变成另一个向量),那么 SVD 的几何意义就是:任何复杂的线性变换,都可以分解为“旋转 -> 拉伸 -> 旋转”三个连续的简单动作。
假设我们在二维平面上有一个单位圆,当我们用矩阵 $A$ 对这个圆进行变换时,它会变成一个倾斜的椭圆。SVD 揭示了这个变形的本质:
第一步 ($V^T$):旋转。 首先,正交矩阵 $V^T$ 对空间进行旋转(或镜像翻转),圆的形状不变。
第二步 ($\Sigma$):拉伸。 对角矩阵 $\Sigma$ 沿着坐标轴对空间进行拉伸或压缩。圆在这个阶段变成了一个椭圆,拉伸的比例就是奇异值。
第三步 ($U$):再次旋转。 最后,正交矩阵 $U$ 将这个椭圆再次旋转到最终的位置。
小结: $V$ 找到了原空间中相互正交的基向量,$\Sigma$ 告诉我们这些基向量被拉伸了多少(也就是有多重要),$U$ 则决定了拉伸后的向量在新空间中的最终方向。
为了让你亲眼看到这个“旋转-拉伸-旋转”的过程,我为你构建了下面的交互式探索工具。你可以尝试改变矩阵 $A$ 的值,观察 SVD 是如何一步步将单位圆变成最终的椭圆的。
三、 奇异值分解的实际应用
为什么我们要在乎奇异值($\Sigma$)?因为奇异值衰减得非常快。在很多实际数据中,前 10% 的奇异值可能就占据了所有奇异值总和的 90% 以上。
这意味着,我们可以忽略掉那些较小的奇异值(把它们当作噪声或不重要的细节),只用最大的几个奇异值来重构原矩阵,这就是所谓的数据截断或降维:
_(其中 $k$ 是我们保留的最大的奇异值数量)
这种思想直接催生了以下经典应用:
1. 图像压缩
一张黑白图片可以看作是一个巨大的矩阵。如果你对这个矩阵进行 SVD,并只保留前几十个最大的奇异值,你会发现虽然扔掉了绝大部分数据,重构出来的图片依然能看清轮廓。保留的奇异值越多,图像越清晰,但这提供了一种极高压缩比的方法。
2. 降维与特征提取(PCA 的亲兄弟)
在机器学习中,当我们面临特征维度过高的问题时(也就是“维度灾难”),我们可以利用 SVD 提取出数据中最重要的“主成分”。事实上,主成分分析(PCA)的底层实现往往就是通过对数据矩阵进行 SVD 来完成的,因为直接计算协方差矩阵的特征值在数值上不够稳定。
3. 推荐系统(协同过滤)
如果你有一个庞大的矩阵,行是用户,列是电影,矩阵里的值是评分。这个矩阵往往是极度稀疏的(大多数人没看过大多数电影)。通过隐语义模型(Latent Factor Model),基于 SVD 的变体可以将这个稀疏矩阵分解,提取出“用户的潜在偏好向量”和“电影的潜在特征向量”,从而预测用户未看过的电影评分,实现精准推荐。
大数定律
大数定律告诉我们:在试验条件不变的情况下,重复试验多次,随机事件的频率会无限趋近于它的概率;样本的平均值会无限趋近于总体的期望值。
交叉熵损失与KL散度
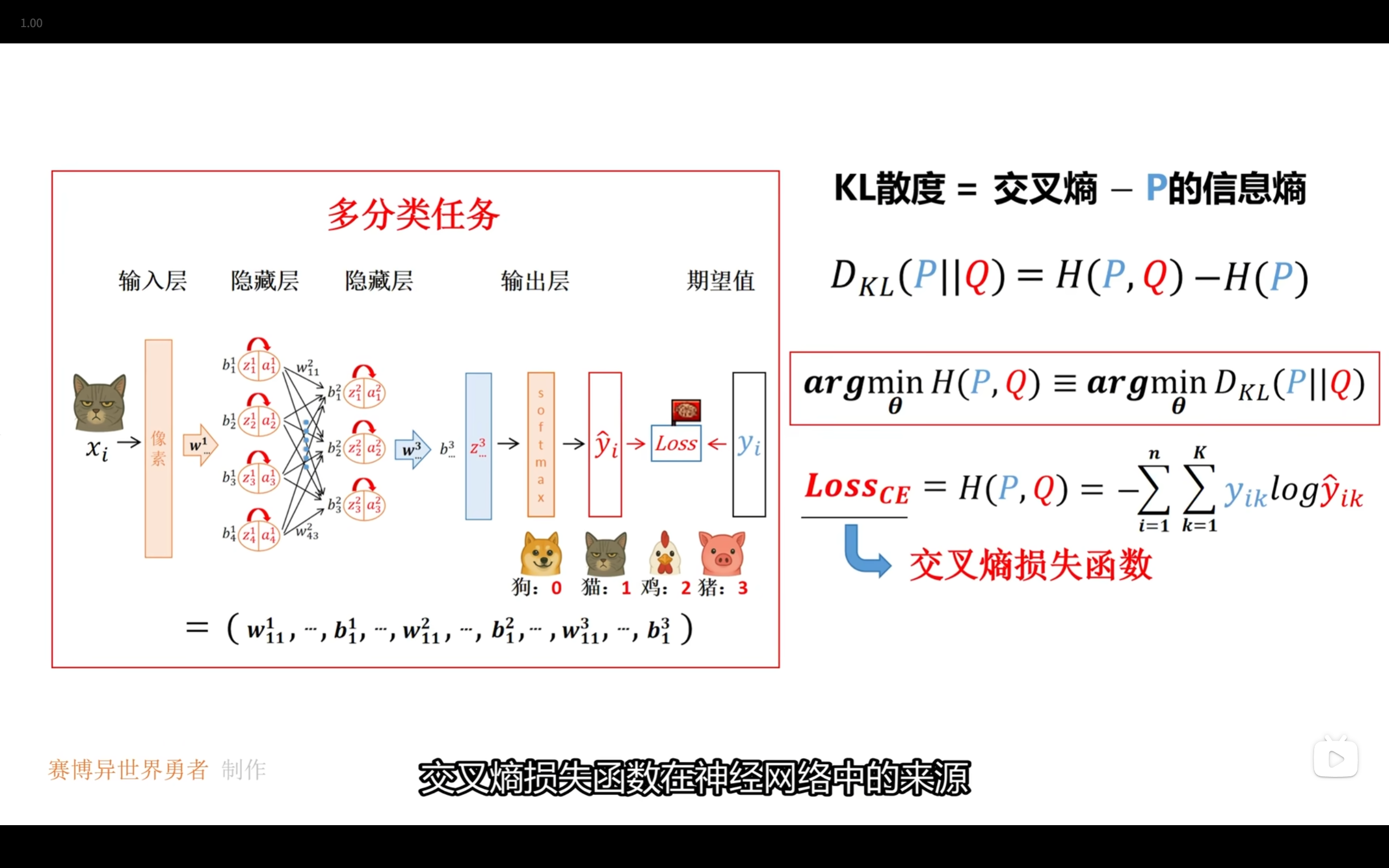
深度学习
损失函数
回归 : MSE
分类 : 交叉熵梯度下降
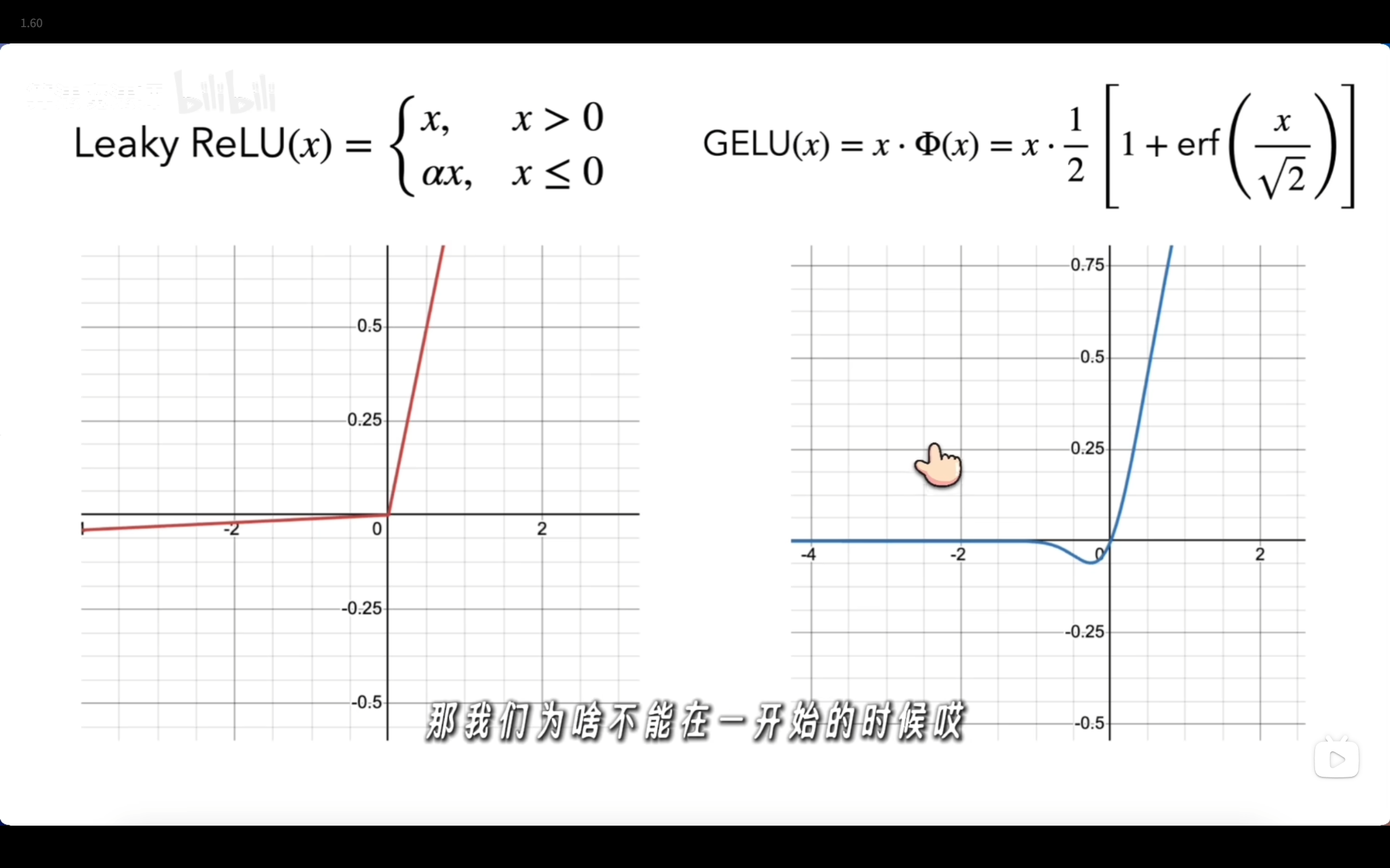
损失函数关于参数求偏导数得到梯度激活函数
目标是引入非线性,让模型拟合更复杂的特征
梯度下降
全量梯度下降 Batch Gradient Descent(BGD)
每一次参数更新,都使用全部训练数据来计算梯度
随机梯度下降 Stochastic Gradient Descent(SGD)
每次只用一个样本来更新参数
批量梯度下降 Mini-batch Gradient Descent(MBGD)
每次用**一小批数据(batch)来更新参数梯度下降优化过程
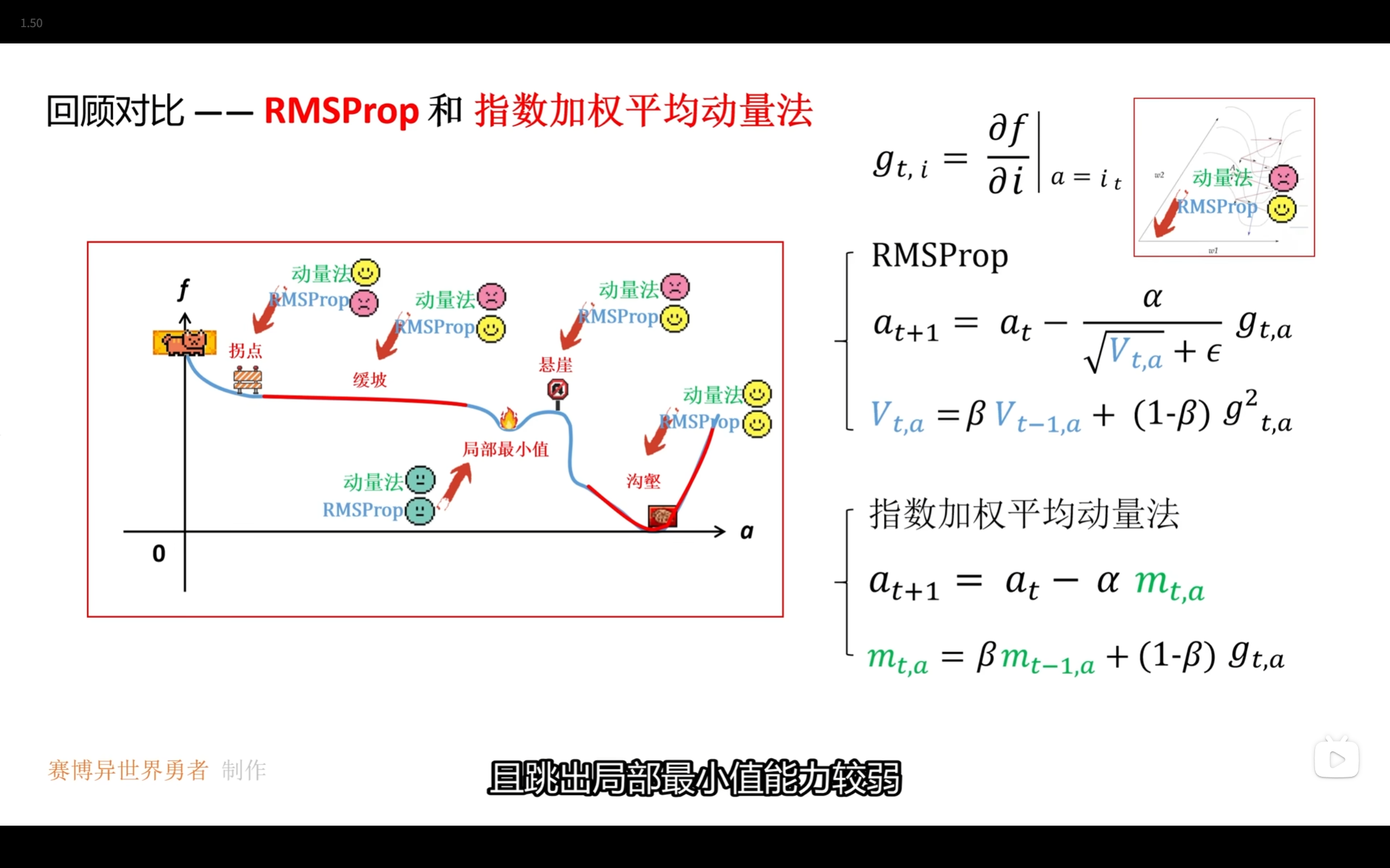
动量法 | RMSProp
动量法:不用当前的梯度来更新参数,而是用梯度的指数加权平均来更新参数,减小模型训练过程的震荡
RMSProp:用梯度平方的指数加权平均来更新参数
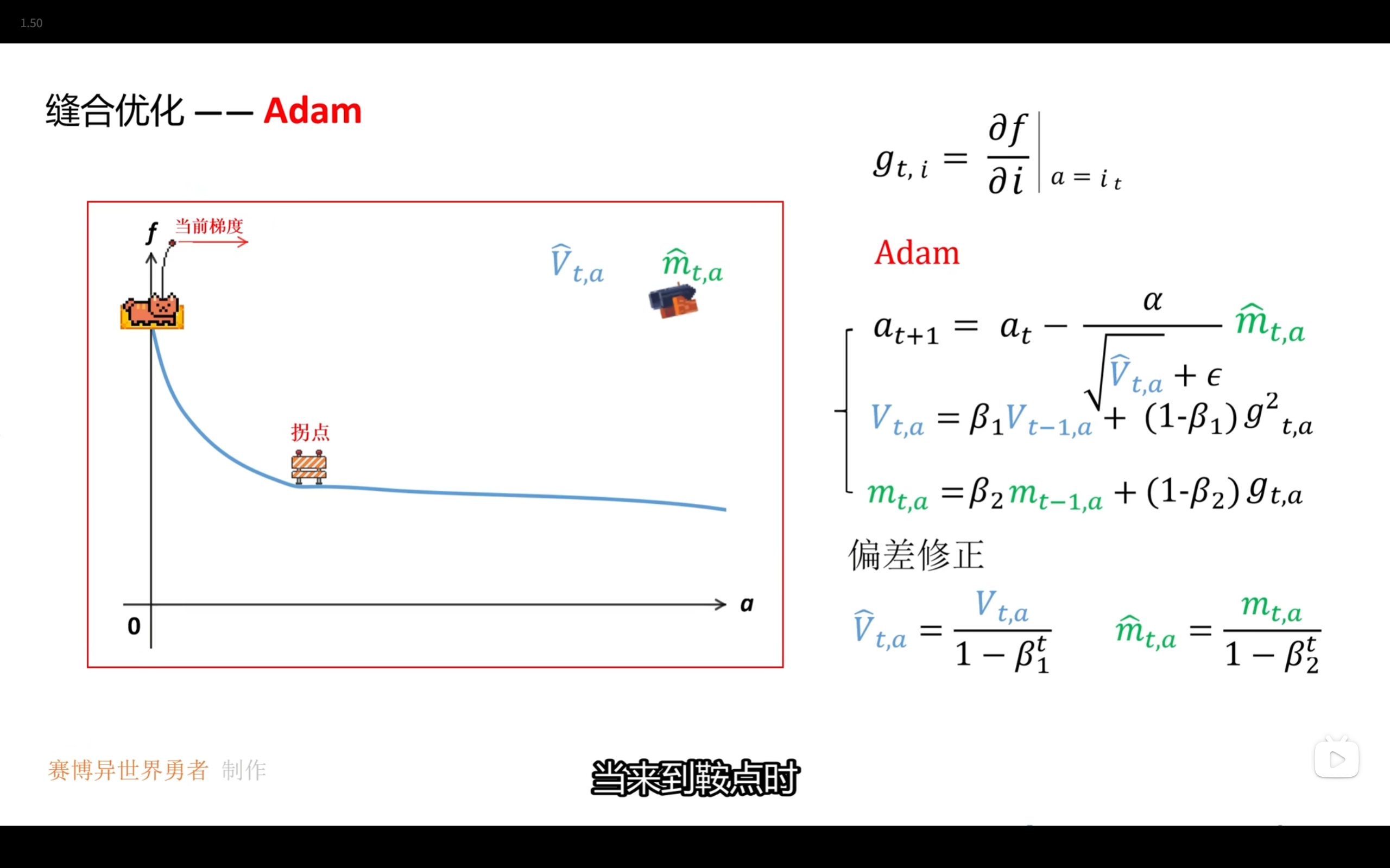
Adam
Adam就是动量法和RSMProp的结合,并将指数加权平均进行修正
AdamW


vllm & Page Attention
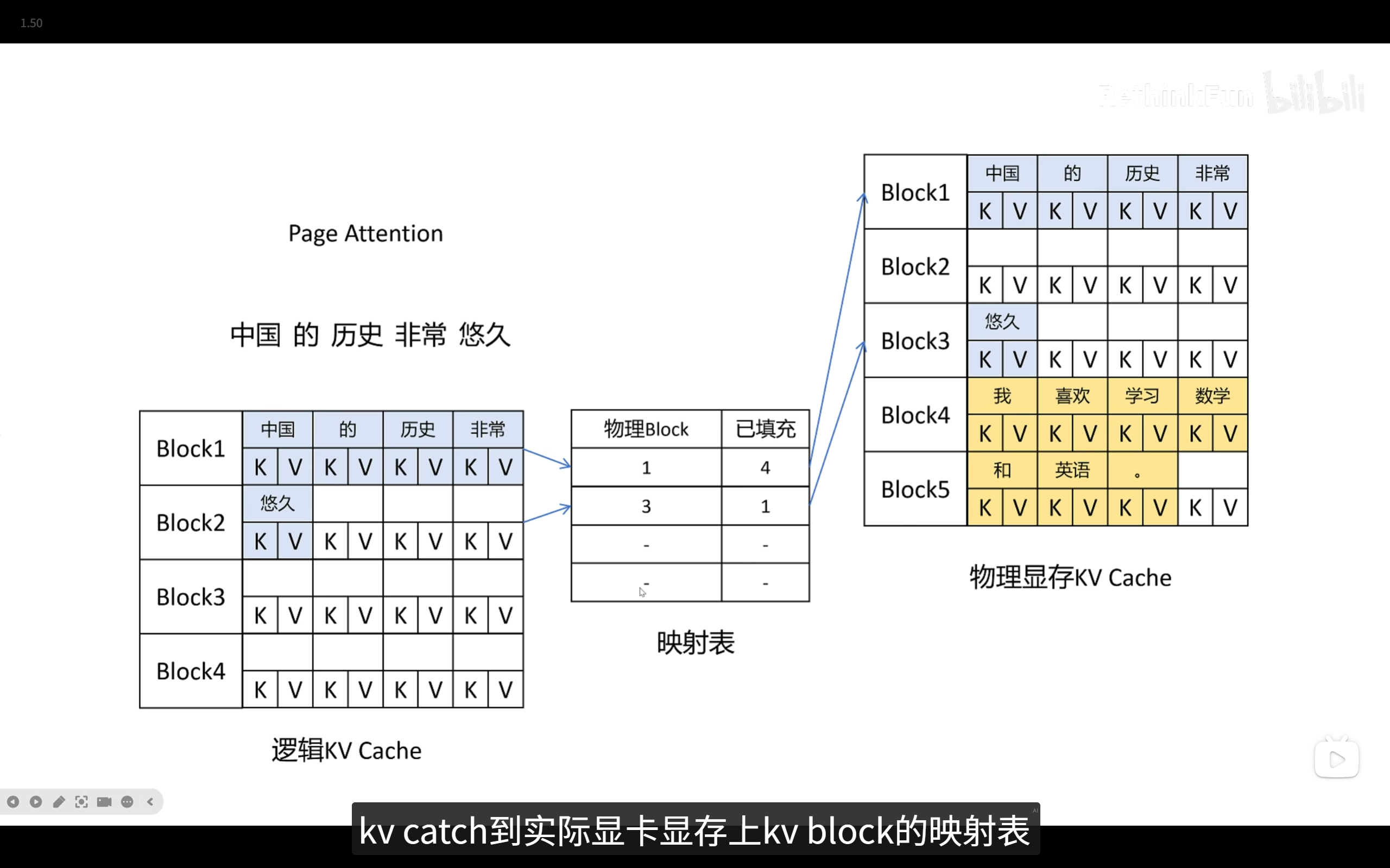
- Page Attention
按需分配,不提前预分配。
按Block分配,减少碎片大小。
虚拟内存,方便实现调用。

一、 传统 KV Cache 的致命痛点:显存碎片化
在 PagedAttention 出现之前,主流的推理框架(如早期的 HuggingFace Transformers)在管理 KV Cache 时,采用的是连续内存分配策略。
因为模型在生成文本之前,并不知道用户最终会生成多长的句子,为了防止生成一半时显存溢出,系统会提前为每个请求分配一段最大可能的连续显存空间(例如预留 2048 个 Token 的位置)。
这就像你去餐厅吃饭:
内部碎片(占着茅坑不拉屎): 你一个人去吃饭,但不确定会不会有朋友来,于是餐厅直接给你留了一张 20 人的大圆桌。结果最后只有你一个人吃,剩下的 19 个座位(显存)全部被浪费了。据 vLLM 论文统计,这种预分配机制会导致 60% - 80% 的显存被浪费。
外部碎片(有空位但坐不下): 随着请求的加入和退出,显存中会出现很多零碎的空闲空间。当一个新的长请求到来时,虽然总空闲空间足够,但因为不连续,系统无法分配,只能拒绝服务。
显存被大量浪费,导致 GPU 能够同时处理的请求数量(Batch Size)上不去,推理吞吐量自然就低得可怜。
二、 PagedAttention 的灵感来源:操作系统的虚拟内存
为了解决这个问题,PagedAttention 借用了计算机操作系统中非常成熟的概念:虚拟内存与分页(Paging)机制。
在操作系统中,程序认为自己拥有一块连续的内存(逻辑内存),但实际上,这块内存在物理上是被切分成一个个固定大小的“页(Page)”,散落在内存条的各个角落(物理内存)。操作系统通过一张页表(Page Table)来记录逻辑地址和物理地址的映射关系。
PagedAttention 完美复刻了这一思想,将其应用到了大模型的 KV Cache 管理中。
三、 PagedAttention 的核心运作机制
切块(Blocks):
它不再为每个请求预分配一大段连续空间,而是将物理显存切分成一个个固定大小的 KV 块(KV Blocks)**。例如,每个块固定只能装 16 个 Token 的 K 和 V 矩阵。
按需分配(动态扩展):
当用户发送 Prompt 时,系统计算出 Prompt 的长度,然后分配刚好够用的几个 KV 块。
在后续生成(Decode)新 Token 的阶段,每生成一个 Token,就塞进当前的块里。当前块塞满后,系统才会在物理显存中随便找一个空闲的新块分配给它。 这种方式彻底消除了大规模的预分配浪费。
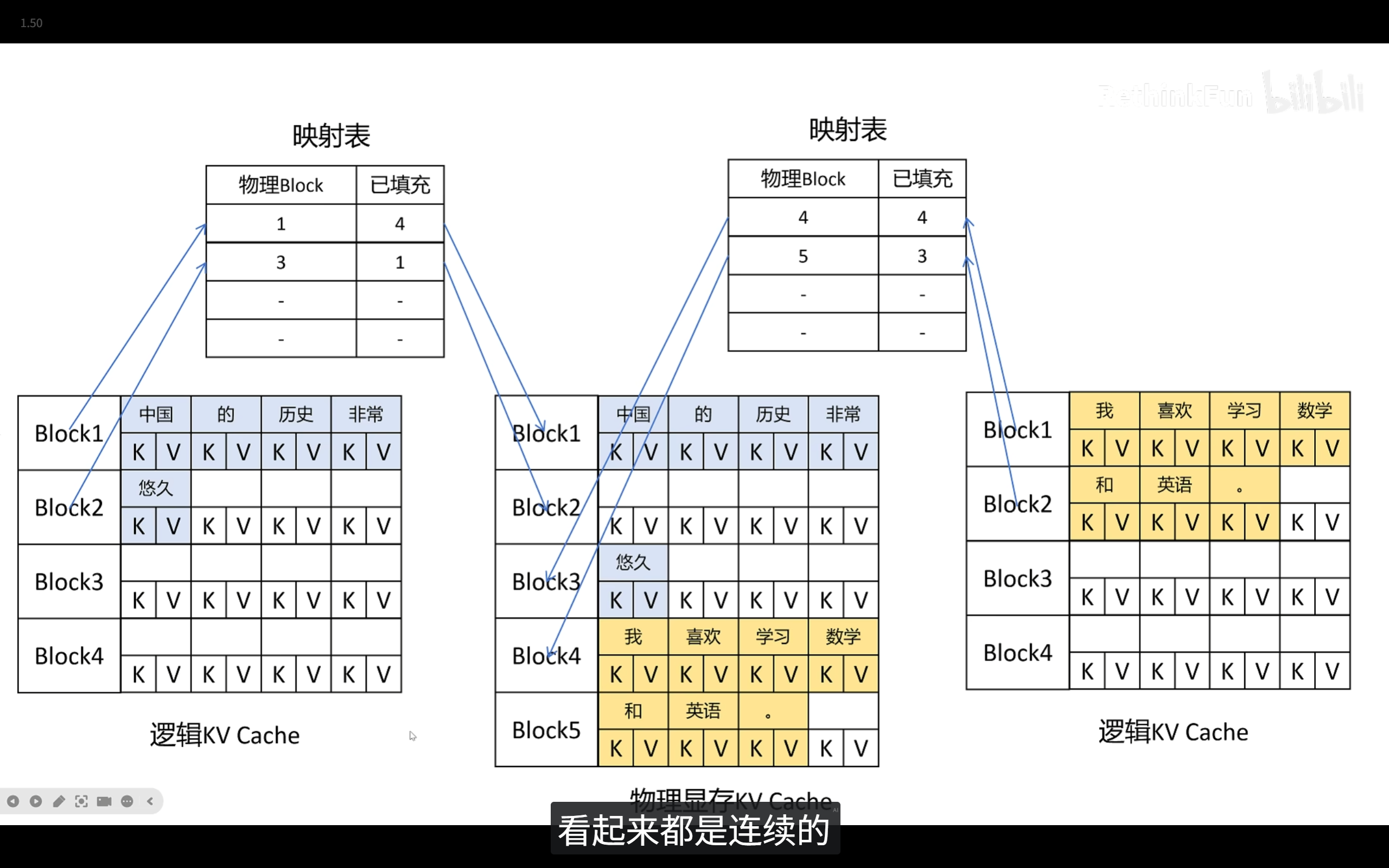
块表映射(Block Table):
模型在计算注意力机制时,需要按顺序读取历史 Token。既然物理内存是被打散的,模型怎么找到它们呢?
PagedAttention 维护了一个 Block Table(块表)。它记录了“逻辑上的连续 Token”对应的“物理上的零散 Block”。当模型需要计算 Attention 时,底层 CUDA 算子会通过查这张表,精准地把打散的物理块拼凑起来参与计算。
四、 PagedAttention 带来的额外红利:内存共享
除了解决碎片化问题,将显存“分页”还带来了一个意想不到的杀手级优势——内存共享(Memory Sharing)。
在很多高级的推理场景中,我们经常遇到需要共享上下文的情况。例如:
- 并行采样(Parallel Sampling): 给定一个相同的 Prompt,让模型同时生成 3 个不同的回答供用户挑选。
- Beam Search: 在解码过程中,保留多个得分较高的分支路径。
在传统方式下,就算 Prompt 是一模一样的,系统也必须为这 3 个回答各自复制一份完整的 Prompt KV Cache。
而在 PagedAttention 中,系统只需要在 Block Table 中将这 3 个回答的物理块指针指向同一块存储 Prompt 的物理块即可。只有当它们开始生成各自不同的回答时,才会采用“写时复制(Copy-on-Write)”机制分配新的块。
这种共享机制使得复杂采样算法下的显存占用锐减,进一步释放了算力。
Flash Attention
Flash Attention 是由 Tri Dao 等人在 2022 年提出的一种针对 Transformer 模型中注意力机制(Attention Mechanism)的硬件感知(Hardware-aware)优化算法。它的核心贡献在于:在数学上等价于标准 Attention 的前提下,大幅降低了显存访问开销,将显存复杂度从 $O(N^2)$ 降到了 $O(N)$,并显著提升了计算速度。
一. 痛点:标准 Attention 的“内存墙”瓶颈
在标准的 Transformer 中,Self-Attention 的计算公式为:
假设序列长度为 $N$,特征维度为 $d$。标准计算过程包含以下步骤:
计算 $S = QK^T$,得到一个 $N \times N$ 的中间矩阵。
对 $S$ 进行缩放并计算 $P = \text{softmax}(S)$,得到一个 $N \times N$ 的注意力分数矩阵。
计算输出 $O = PV$,得到最终的 $N \times d$ 矩阵。
问题在哪里?
GPU 的算力(FLOPs)增长极快,但显存带宽(Memory Bandwidth)的增长却相对缓慢。GPU 的存储分为两层:
HBM (高带宽内存):也就是我们常说的显存(如 80GB 的 A100),容量大但读写速度相对较慢。
SRAM (静态随机存取存储器):GPU 计算单元旁边的高速缓存,速度极快但容量极小(单块 GPU 上通常只有十几 MB)。
在标准 Attention 中,生成 $N \times N$ 的中间矩阵 $S$ 和 $P$ 时,GPU 必须将庞大的数据从 HBM 读到 SRAM,计算完毕后再写回 HBM。当序列长度 $N$ 变大(例如达到 $32k$ 或 $100k$)时,$N \times N$ 的矩阵会变得异常庞大。频繁地在 HBM 和 SRAM 之间读写这些庞大的中间矩阵,导致了严重的 IO 瓶颈(即“内存墙”)。 大部分时间 GPU 都在等数据传输,而不是在做计算。
二. Flash Attention 的核心机制
Flash Attention 的核心思路是 IO-Aware(感知输入输出),即尽可能减少 HBM 的读写次数。它主要通过两个核心技术实现:Tiling(分块计算) 和 Recomputation(重计算)。
A. Tiling(分块计算与 Online Softmax)
为了避免生成庞大的 $N \times N$ 中间矩阵,Flash Attention 将输入矩阵 $Q, K, V$ 切分成多个小块(Blocks)。
它将这些小块从慢速的 HBM 加载到快速的 SRAM 中。
在 SRAM 内部直接完成 Attention 的前向计算,并直接将最终结果($N \times d$ 大小)写回 HBM。
数学上的难点:Softmax 的分块计算
标准的 Softmax 需要知道全局的信息。计算 Softmax 时,需要计算所有元素的指数和作为分母:$f(xi) = \frac{e^{x_i}}{\sum{j=1}^{N} e^{x_j}}$。如果只加载一部分数据,怎么计算 Softmax?
Flash Attention 引入了 Online Softmax 的思想。通过维护两个局部变量(局部的最大值 $m$ 和局部的指数和 $l$),算法可以在处理下一个块时,利用简单的数学公式对之前的分母和最大值进行更新(Rescaling)。这样就可以在不读取完整行的情况下,一边分块加载数据,一边计算出全局精确的 Softmax 结果。
B. Recomputation(重计算节省显存)
在神经网络的训练过程中,反向传播(Backward Pass)计算梯度时,通常需要用到前向传播时保存的中间激活值(Activation)。对于标准 Attention,这意味着必须在显存(HBM)中保存那个庞大的 $N \times N$ 矩阵 $P$。
Flash Attention 为了把空间复杂度降到 $O(N)$,丢弃了前向传播阶段的 $N \times N$ 中间矩阵。
- 取而代之的是,它只保存了分块计算 Softmax 时的归一化常数(即前向传播中的局部最大值 $m$ 和指数和 $l$)。
- 在反向传播时,利用保存的这些常数和输入的 $Q, K, V$(只有 $O(N)$ 复杂度),在快速的 SRAM 中重新计算出注意力矩阵并立刻用于梯度计算。
由于在 SRAM 中的计算速度极快,这种“以计算换显存”的做法,不仅大幅降低了显存占用,实际上总体速度也因为省去了 HBM 的读写时间而变快了。
三. Flash Attention 的演进
- Flash Attention (v1):证明了 IO-aware 优化的有效性,解决了长序列 Attention 的 $O(N^2)$ 显存和耗时问题,带来了 2-4 倍的加速。
- Flash Attention-2 (2023):针对矩阵乘法(MatMul)和非矩阵乘法(Softmax、Rescale)的计算分配进行了深度优化。它改进了 GPU 内部 Thread block (线程块) 和 Warp (线程束) 的任务分配,大幅减少了同步开销,使计算效率接近了 GPU 的理论极限(达到算力利用率的 70% 左右)。
- Flash Attention-3 (2024):专门针对 NVIDIA 的最新架构(如 Hopper H100)进行了优化。利用了 Hopper 架构的新特性,如异步执行(Asynchronous Execution)、Warp Group 级别的指令以及对 FP8 数据格式的原生支持,进一步提升了性能。
KV Cache
KV Cache(Key-Value Cache)是大型语言模型(LLM)推理加速中最核心、最基础的技术之一。简单来说,它是一种“空间换时间”的策略,用来解决 Transformer 模型在生成文本时大量重复计算的问题。
一、 为什么需要 KV Cache?(背景与痛点)
目前主流的大语言模型(如 GPT-4, LLaMA, Qwen)大多采用基于 Transformer Decoder-only 的架构,它们的文本生成方式是自回归(Autoregressive) 的。也就是说,模型每次只能预测并生成下一个 Token。
假设我们要让模型输出句子:“我喜欢人工智能”。
输入
[我],模型预测出[喜]。输入
[我, 喜],模型预测出[欢]。输入
[我, 喜, 欢],模型预测出[人]。
在没有 KV Cache 的情况下,当模型预测 [人] 时,它需要把前面的 [我], [喜], [欢] 重新过一遍 Transformer 的每一层,重新计算它们的 Query (Q), Key (K) 和 Value (V) 矩阵。随着生成序列越来越长,这种历史数据的重复计算量会呈指数级增长,导致推理速度越来越慢。
二、 KV Cache 的工作原理(解决方案)
在 Transformer 的注意力机制(Self-Attention)中,注意力分数的计算公式为:
我们发现,在预测新 Token 时,历史 Token 的 K 和 V 矩阵是固定的,只有最新一个 Token 的 Q 需要和所有历史 Token 的 K 去计算注意力分数。
因此,KV Cache 的核心思想就是:把过去生成的 Token 对应的 Key (K) 和 Value (V) 张量保存在显存中。
推理过程被划分为了两个截然不同的阶段:
Prefill(预填充阶段):
这是模型处理用户输入的 Prompt(提示词)的阶段。
模型会并行处理所有的输入 Token,一次性计算出它们所有的 Q、K、V。
在这个阶段,系统会将这些初始 Token 的 K 和 V 存入缓存(Cache)中。
此阶段计算密集,但只发生一次。
Decode(解码阶段):
这是模型逐个生成新 Token 的阶段。
当需要生成第 $N$ 个 Token 时,模型只计算第 $N-1$ 个 Token 的 Q、K、V。
模型从缓存中取出之前 $1$ 到 $N-2$ 个 Token 的 K 和 V,与当前新的 K、V 拼接(Concatenate)。
利用拼接后的完整 K、V 和当前的 Q 计算注意力机制,得出下一个 Token。
将新生成的 K 和 V 写入缓存,供下一步使用。
通过这种方式,时间复杂度从 $O(N^2)$ 降到了 $O(N)$,极大地提高了生成速度。
三、 KV Cache 的代价
虽然省了时间,但 KV Cache 需要消耗大量的显存。很多时候,LLM 推理的瓶颈不在算力,而在显存的容量和带宽。
计算一个 Token 在模型中产生的 KV Cache 大小的基础公式为:
(注:乘以 2 是因为要存 K 和 V 两个矩阵)
以 LLaMA-2-7B 为例(32层,Hidden Size 4096,使用 FP16 精度即2字节):
单 Token 的 KV Cache = $2 \times 32 \times 4096 \times 2 = 524,288$ 字节 $\approx 512$ KB。
如果上下文长度达到 4096,且 Batch Size 为 1,则 KV Cache 大小 = $512 \text{ KB} \times 4096 \approx 2$ GB。
如果是高并发场景,Batch Size 达到 32,光是 KV Cache 就会吃掉 64 GB 的显存!
四、 针对 KV Cache 的前沿优化技术
为了缓解 KV Cache 带来的显存压力,业界提出了多种架构和工程上的优化:
MQA (Multi-Query Attention) / GQA (Grouped-Query Attention): 在模型架构层面,让多个 Query 头共享同一组 Key 和 Value 头,从而在物理上将 KV Cache 的大小缩减几倍甚至十几倍(LLaMA-2 70B 和 LLaMA-3 都采用了 GQA)。
PagedAttention (vLLM框架的核心): 借鉴操作系统的虚拟内存和分页机制,将 KV Cache 划分为固定大小的块(Blocks),解决传统连续内存分配导致的显存碎片化问题,极大提升了 GPU 的并发吞吐量。
KV Cache quantization (量化): 将 K 和 V 矩阵从 FP16(16位)压缩到 INT8 甚至 INT4(8位或4位),用极少的精度损失换取显存占用减半或减少 75%。
Qwen系列
Qwen 是阿里开源的大模型体系,采用 Transformer + GQA + RoPE + RMSNorm,覆盖文本、多模态和 Agent,具有强中文能力和工程落地优势,是当前最主流的开源大模型之一。
Qwen(通义千问)系列是目前开源社区中最活跃、进化速度最快的大模型家族之一。研究它的演进路线,实际上也是在宏观地梳理近两年大语言模型(LLM)以及多模态大模型架构的通用发展趋势。
以下是 Qwen 系列从初代至今的核心演进与变化详解:
一、 版本迭代与核心里程碑
1. Qwen (V1):奠定基础与多模态的早期探索
初代 Qwen 确立了其扎实的底层基础。它采用了标准的 Transformer 架构,并引入了当时业界验证最有效的技术:RoPE(旋转位置编码)、SwiGLU 激活函数、RMSNorm 以及 FlashAttention。
- 语言能力: 重点深耕中英双语,使用了高达 3T tokens 的高质量预训练数据。
- 多模态试水: 在这阶段同步推出了 Qwen-VL(视觉-语言)和 Qwen-Audio(音频-语言)。这是非常关键的一步,展现了其向多模态领域拓展的野心,采用了将视觉/音频编码器与 LLM 基座拼接的经典范式。
2. Qwen1.5:生态对齐与架构微调
Qwen1.5 并非简单的过渡版本,而是一次重大的“底层重构”和开源生态的全面拥抱。
- Hugging Face 原生支持: 彻底放弃了原先自定义的
modeling_qwen.py代码,完全整合进 Transformers 库,极大地降低了开发者的部署和微调门槛。 - 全面引入 GQA(分组查询注意力): 为了提升推理效率和降低显存占用,Qwen1.5 在所有尺寸的模型(从 0.5B 到 72B)中都应用了 GQA,而不再局限于传统的 MHA(多头注意力)。
- 探索 MoE 架构: 推出了 Qwen1.5-MoE,开始在稠密模型(Dense)之外,利用混合专家架构来平衡参数规模与推理成本。
3. Qwen2:全面升级与多语言扩展
Qwen2 是一次全方位的跨越,模型在各项榜单上开始对标甚至超越部分闭源头部模型。
- 架构微调(Tie Embeddings): Qwen2 引入了 Tie word embeddings(绑定词嵌入)技术,让输入和输出层共享参数,在不牺牲性能的前提下减少了模型参数量。
- 上下文长度暴增: 从前代的 8K/32K 级别,全面提升至支持 128K tokens 的超长上下文。
- 多语言语料大爆发: 不再局限于中英双语,预训练数据中大幅增加了额外 27 种语言的数据,真正走向国际化。
- 多模态的深度进化: 推出了 Qwen2-VL。与初代 VL 不同,Qwen2-VL 引入了动态分辨率支持(无需将图片缩放到固定尺寸)以及强大的视频理解能力,多模态融合的深度和效果有了质的飞跃。
4. Qwen2.5:数据标度律的极致压榨与领域专家
这是目前最新的主力版本,其核心变化在于数据规模的爆炸式增长和垂直领域的极致强化。
- 18T Tokens 的预训练: 训练数据量从前代的几 T 直接跃升至 18T tokens。这证明了在架构相对稳定的情况下,极其庞大且高质量的数据依然能带来显著的性能提升(Scaling Law 的延续)。
- 代码与数学的突破: 推出了专门的 Qwen2.5-Coder 和 Qwen2.5-Math。它们不再是简单的微调版本,而是在预训练阶段就注入了海量的垂直领域数据,使其在复杂逻辑推理、代码生成上达到了开源界的顶尖水平。
二、 核心架构与策略的演变趋势总结
纵观整个 Qwen 系列的发展,我们可以提炼出几个清晰的技术演变主线:
- 注意力机制的降本增效: 从 MHA(多头注意力)全面转向 GQA(分组查询注意力),这是为了在模型规模不断扩大的同时,保证长文本推理时的 KV Cache 显存占用处于可控范围内。
- 多模态融合从“插件”走向“原生”: 早期的多模态模型更多是“视觉编码器 + LLM”的生硬拼接。而到了 Qwen2-VL,模型对图像分辨率的动态适应能力增强,视觉特征与语言特征的对齐更加深层,多模态理解变得更加原生和自然。
- 模型范式的多元化: 形成了“Dense(稠密模型) + MoE(混合专家模型)”双线并行的格局。同时,在通用基座之外,越来越重视 Math 和 Coder 这类能够大幅提升模型底层“System 2(慢思考/逻辑推理)”能力的垂直专家模型。
- Token 词表的优化: 随着版本的迭代,其 Tokenizer 的词表大小和分词效率也在不断优化,以更高效地压缩多语言代码和复杂符号。
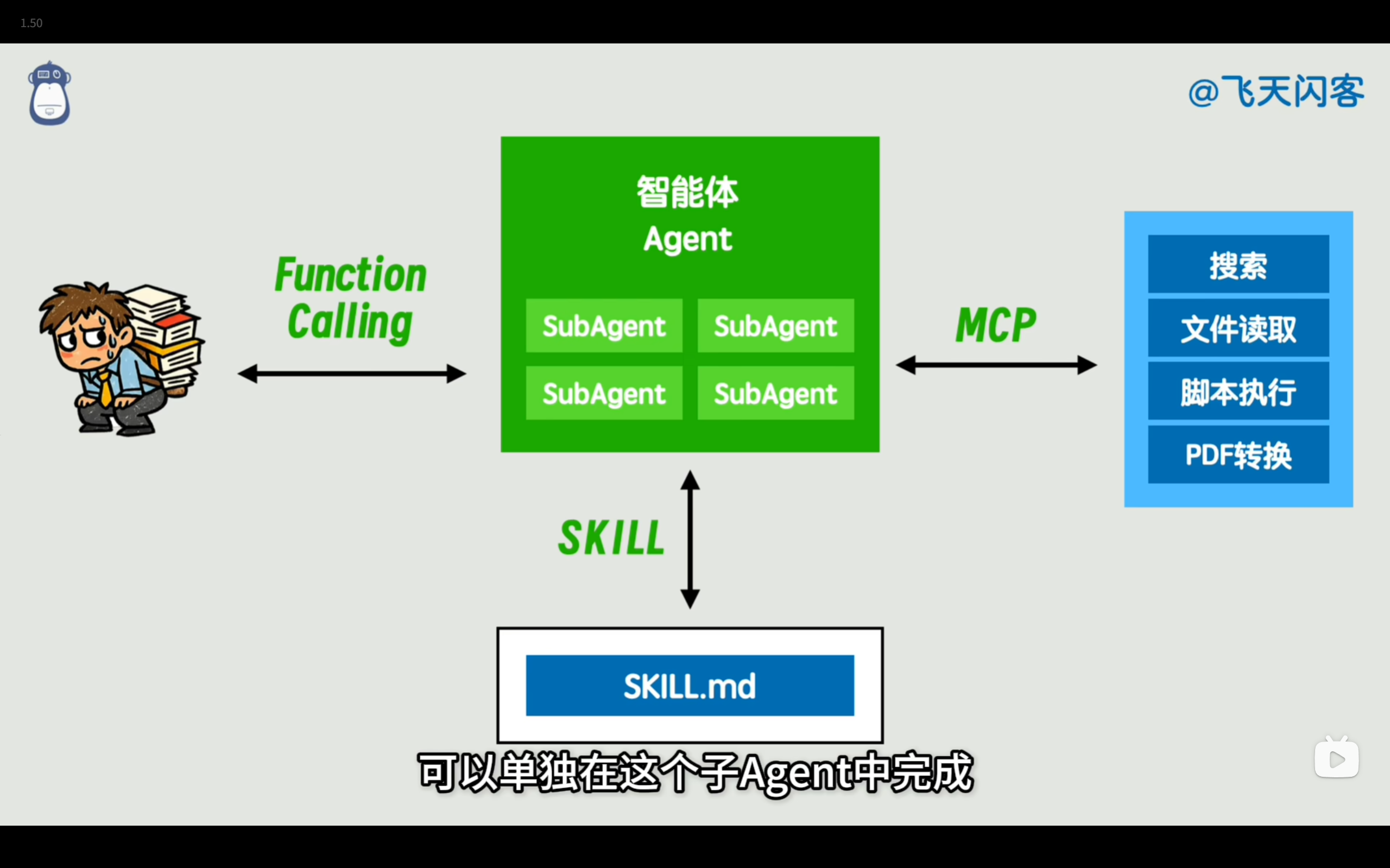
LangChain | Workflow | Function call | MCP | Skill | Sub Agent | Harness
MOE
混合专家架构(Mixture of Experts, MoE)是当前大语言模型(LLM)和多模态大模型突破算力瓶颈、实现参数规模指数级扩张的核心技术路径。与传统的稠密(Dense)模型不同,MoE 是一种稀疏激活(Sparse Activation) 架构,它能够在保持计算浮点运算次数(FLOPs)基本不变的前提下,大幅增加模型的总参数量。
以下是 MoE 架构的核心技术细节及工程实现剖析。
一. 架构核心组件与数学表达
在主流的 Transformer 架构中,MoE 通常用于替换标准 Transformer 块中的前馈神经网络(FFN)层。因为在 Dense 模型中,FFN 层占据了约 2/3 的参数量。
MoE 层主要由两个部分组成:
- 专家网络(Experts): $N$ 个结构相同但权重独立的神经网络(通常是 FFN)。记为 $E_1, E_2, …, E_N$。
- 门控网络 / 路由网络(Gating Network / Router): 决定将当前输入的 Token 分配给哪几个专家进行处理。
对于输入 $x$,MoE 层的输出 $y$ 是各个专家输出的加权和:其中,$gi(x)$ 是门控网络输出的第 $i$ 个专家的路由权重,且满足 $\sum{i=1}^{N} g_i(x) = 1$。
二. 稀疏路由机制 (Sparse Routing)
如果让所有的 $g_i(x)$ 都大于 0,那就是对所有专家进行密集计算,这违背了 MoE 节省算力的初衷。因此,现代大模型(如 Mixtral 8x7B、DeepSeek-V2 等)通常采用 Top-K 路由机制:
门控网络通过一个线性层 $W_g$ 计算出当前 Token 对所有专家的偏好分数。$\text{TopK}$ 函数会将得分最高的 $K$ 个专家的分数保留,其余置为 $-\infty$。经过 Softmax 后,只有这 $K$ 个专家的权重为非零值。
- 通常 $K \ll N$(例如 $N=8, K=2$)。这意味着对于每一个 Token,只有 2 个专家被激活并参与前向和反向传播运算。
三. 模型训练与负载均衡 (Load Balancing)
MoE 架构在训练时面临的一个致命问题是路由崩塌(Routing Collapse):门控网络可能会倾向于把绝大多数 Token 都发送给少数几个“训练得更好”的专家,导致这些专家过载,而其他专家“饿死”(得不到更新)。
为了解决这个问题,需要在总损失函数中引入负载均衡损失(Load Balancing Loss):
- $f_i$:在一个 Batch 中,路由到第 $i$ 个专家的 Token 比例。
- $P_i$:门控网络分配给第 $i$ 个专家的平均路由权重。
- $\alpha$:乘法系数,用于调节辅助损失的权重。
通过最小化 $L_{aux}$,可以强迫模型将 Token 尽可能均匀地分配给所有专家。
四 部署与系统的挑战 (系统级视角)
对于专注于底层推理优化和框架(如 vLLM)的开发者来说,MoE 带来了与 Dense 模型截然不同的系统级挑战:
- 专家容量 (Expert Capacity) 与 Token Dropping:
在硬件实现中,张量的大小必须是静态的。因此,需要预先设定每个专家能够接收的最大 Token 数量(Capacity)。 如果路由到某专家的 Token 数超过了容量上限,多余的 Token 就会被丢弃(Token Dropping)或者通过残差连接直接跳过该层(具体取决于模型设计)。 - 显存带宽瓶颈 (Memory Bandwidth Bound):
MoE 模型在推理(特别是 Decoding 阶段)时,Batch Size 通常较小(例如单用户对话)。此时,为了处理极少量的 Token,仍然需要将庞大的专家权重从 GPU 的 HBM 加载到 SRAM 中。这使得 MoE 推理往往是内存带宽受限(Memory-bound)的,而非计算受限。这也是为什么在 vLLM 等框架中,针对 MoE 的 PagedAttention 优化和显存管理尤为重要。 - 专家并行 (Expert Parallelism, EP) 与 All-to-All 通信:
在分布式训练和多卡推理时,由于参数量巨大,通常会采用专家并行(EP),将不同的专家放置在不同的 GPU 上。这引入了昂贵的跨节点/跨卡 All-to-All 通信开销(Token 需要被分发到拥有对应专家的 GPU 上,计算完后再汇聚回来)。
PPO/GRPO/DPO
深入研究大模型的对齐与强化学习(RL)阶段,确实是目前把握核心大模型(尤其是向多模态大模型演进时)最关键、也最具挑战性的部分。这个领域迭代极快,从最初复杂的基于人类反馈的强化学习(RLHF),到现在的直接偏好优化(DPO)及其变体,核心目标都是在稳定性和显存开销之间寻找最优解。
一、 经典阵营:基于奖励模型的 RLHF (以 PPO 为代表)
这是 OpenAI 在 InstructGPT 和 ChatGPT 中使用的经典范式。它严格遵循三个步骤:监督微调 (SFT) $\rightarrow$ 训练奖励模型 (RM) $\rightarrow$ 强化学习优化。
核心算法:PPO (Proximal Policy Optimization)
原理:PPO 是一种策略梯度算法。在这一阶段,大模型本身充当“Actor(策略)”,它生成回复,然后由事先训练好的奖励模型(Reward Model)给出评分。为了防止模型为了骗取高分而生成毫无逻辑的乱码(Reward Hacking),PPO 引入了 KL 散度惩罚项。
核心目标函数:
(注:$\pi\theta$ 是当前训练的模型,$\pi{ref}$ 是冻结的 SFT 初始模型,$R$ 是奖励模型,$\beta$ 是控制 KL 惩罚力度的超参数。)
工程痛点:极其消耗显存。标准的 PPO 在训练时需要同时在显存中加载 4个模型:Actor 模型(训练中)、Reference 模型(冻结,用于算 KL 散度)、Reward 模型(冻结,用于打分)、Critic 模型(训练中,用于估计 Value Function)。即使配合 PyTorch 和 DeepSpeed,集群配置门槛也极高。
二、 革命阵营:直接偏好优化 (Direct Alignment)
因为 PPO 的工程落地难度太大,斯坦福在 2023 年提出了 DPO。DPO 彻底改变了游戏规则,直接干掉了奖励模型 (RM)。
1. DPO (Direct Preference Optimization)
原理:DPO 利用了一个数学上的等价替换。它证明了在最优策略下,奖励函数可以被表示为最优策略与参考策略概率之比的对数。因此,我们可以直接用偏好数据(一个好回答 $y_w$,一个坏回答 $y_l$)去优化语言模型本身,把 LLM 当作自己的奖励模型。
DPO 损失函数:
优势:只需要加载 2个模型(Actor 和 Reference),训练极其稳定,没有 PPO 那种复杂的超参数调优,目前在 HuggingFace
trl库中支持得非常完善,是目前开源界对齐模型的首选。
2. KTO (Kahneman-Tversky Optimization)
演进背景:DPO 虽然好,但它需要严格的“成对数据”(同一个问题,必须有一个好回答和一个坏回答)。而在现实中,我们往往只有“点赞(👍)”或“踩(👎)”的独立数据。
原理:结合了行为经济学中的前景理论。它不依赖成对的偏好,只需要知道一条数据是“被渴望的”还是“不被渴望的”,就能最大化模型的效用。
3. ORPO (Odds Ratio Preference Optimization)
演进背景:DPO 还需要加载一个 Reference 模型,显存还是有点大。并且 DPO 通常需要在一个已经 SFT 过的模型上进行。
原理:ORPO 更进一步,把 SFT 和对齐训练合并成了一步。它甚至不需要 Reference 模型。它通过在标准交叉熵损失(SFT 的损失)上加上一个“优势比(Odds Ratio)”惩罚项,在微调的同时拉开好回答和坏回答的概率差距。这对于算力有限的实验室环境非常友好。
GRPO (Group Relative Policy Optimization,组内相对策略优化) 是由 DeepSeek 团队(在 DeepSeekMath 以及近期爆火的 DeepSeek-R1 中)提出并发扬光大的强化学习算法。它本质上是 PPO 的一种极简、高效变体,专门为了解决 PPO 显存开销过大和训练复杂的问题而生。
要理解 GRPO 有多巧妙,我们需要先看看它到底“砍掉”了 PPO 里的什么东西。
一、 PPO 的痛点:庞大的 Critic 模型
我们在前面提到,标准的 PPO 需要同时加载 4 个模型。其中最让人头疼的是 Critic 模型(价值模型 Value Model)。
在 PPO 中,为了判断一个动作(生成的词)好不好,我们需要一个“基准线(Baseline)”。
Critic 模型的作用就是预测这个状态下“本来应该得多少分”。如果实际得分高于 Critic 的预测,说明表现超常(Advantage > 0),就鼓励;反之则抑制。
痛点:Critic 模型通常和正在训练的 Actor 模型一样大!为了算一个基准线,搭进去了一倍的显存和计算量。
二、 GRPO 的核心魔法:用“组内比较”替代 Critic
GRPO 的核心思想就藏在它的名字里:组内相对(Group Relative)。它直接彻底抛弃了 Critic 模型,转而用统计学的方法在一个批次内部自己生成基准线。
它的运行机制非常直观:
分组生成:对于同一个输入问题(Prompt),让当前模型(Actor)一次性生成 $G$ 个不同的回答(比如生成 4 个或 8 个答案)。
独立打分:用奖励模型(或规则)给这 $G$ 个回答分别打分,得到一组原始分数 $r_1, r_2, \dots, r_G$。
计算基准:计算这组分数的平均值 $\mu$ 和标准差 $\sigma$。
相对优势(Advantage)计算:对每个回答的得分进行标准化(Z-score),得到它的相对优势:
- 策略更新:用这个相对优势 $A_i$ 去更新模型权重。在这一组里,比平均分高的回答($A_i > 0$)概率会被提升,比平均分低的回答概率会被降低。
三、 为什么 GRPO 是游戏规则的改变者?
极致的显存节省
因为它砍掉了 Critic 模型,显存压力骤降。这意味着在同样的硬件下,你可以训练参数量大得多的模型,或者把 Batch Size 和 Context Length 拉得更长。天然契合“长思考”与推理(Reasoning)任务
像数学题和代码生成,对错是非常明确的。在 GRPO 框架下,你甚至不需要训练一个神经网络作为奖励模型(Reward Model)。你可以直接用基于规则的验证器(Rule-based Verifier):答案对了给 1 分,格式符合
<think>标签要求给 0.5 分,编译报错给 0 分。Actor 模型 + 冻结的 Reference 模型 + 规则打分脚本 $\rightarrow$ 就能让模型在无数次“自己和自己比”中左脚踩右脚上天,这就是 DeepSeek-R1 涌现出强大推理能力的核心密码。
模型量化、剪枝、蒸馏
面试关键问题
1.奖励函数是如何设计的
【面试官视角】: 他想知道你是否真的懂 RL,还是只是调了个包;更想知道你是如何把业务目标(查出代码漏洞)转化为模型可以学习的数学梯度的。
【答题话术建议】: “在设计 GRPO 的奖励函数时,我没有采用传统 RLHF 里那种单独训练一个神经网络作为判分器(Reward Model)的做法,而是根据密码 API 检测任务的严谨性,设计了一套完全可编程、离散化、基于规则的组合奖励函数 。
具体来说,我们将总奖励分解为四个维度 :
结构合规奖励 ($r_{struct}$):为了保证系统能解析大模型的输出,模型必须严格遵循 JSON Schema 。如果格式全对,给基础分;有残缺,直接给 0 分或负分。这用 KL 散度正则限制在 SFT 模型附近,防止奖励黑客(Reward Hacking) 。
主判决奖励 ($r_{corr}$):也就是模型判断这段代码到底‘有没有错’(True/False),这是最核心的监督信号 。
误用分型奖励 ($r_{etype}$):如果判定有错,模型给出的具体错误类型(比如是‘静态盐值’还是‘弱随机数’)是否与标准答案一致 。
证据一致性奖励 ($r_{evid}$):这是防幻觉的关键。模型不能只说有错,还必须准确框出漏洞在第几行(证据行)。只有当提取的证据行能支撑前面的判定时,才给分 。
总结亮点: 这种基于规则的组合奖励,在 GRPO 组内相对优势($A_i = R_i - \overline{R}$)的计算下,能够非常明确地告诉模型‘哪种回答是完美的’,既避免了训练 Critic 模型的显存开销,又彻底消除了神经网络判分器常见的‘看图说话’式的幻觉 。”
2. 对 LangChain 的理解与设计?(LangChain Architecture)
【面试官视角】: 他想考察你对大模型应用架构(Agentic Workflow)的理解,是不是把 LLM 当成了一个简单的 API 调用,还是深刻理解了“大模型作为大脑,工具作为手脚”的理念。
【答题话术建议】: “在我们的系统中,我并没有把大模型当成一个简单的黑盒接口,而是把 LangChain 作为整个系统的‘智能中枢(Agent)和工作流编排引擎’ 。
我使用 LangChain 将原本碎片的流程固化成了一个可追溯的有向无环图(DAG) :
调度与路由:当用户上传代码后,LangChain 首先调度‘代码切片器 Tool’,调用 Tree-sitter 提取 AST/CFG,把几千行的代码浓缩成包含控制流的‘最小证据上下文’ 。
检索增强(RAG)融合:然后,LangChain 驱动嵌入模型和向量数据库 ,去检索国密规范知识库,把相关的合规要求注入到 Prompt 中 。
决策与验证闭环:最后,大模型根据上下文做出判决。如果输出格式不对,或者证据链不完整,LangChain 会拦截并要求大模型进行自我反思和修正 。
总结亮点: 对我来说,LangChain 的设计哲学在于解耦与编排。它把确定性的程序分析(静态切片)和概率性的大模型推理无缝结合 ,实现了‘取证 $\rightarrow$ 切片 $\rightarrow$ 判别 $\rightarrow$ 验证 $\rightarrow$ 报告’的端到端自动化 。”
3. 基于 vLLM 部署 PagedAttention 是如何实现的?(vLLM & PagedAttention)
【面试官视角】: 重点考察底层 Infra 能力。如果你只会用 transformers 的 generate 跑推理,是过不了大模型算法岗面试的。你需要讲清楚 PagedAttention 到底解决了什么物理内存问题。
【答题话术建议】:
“在项目初期,我们遇到了严重的推理瓶颈。在处理长代码切片时,自回归解码带来的 KV Cache 会迅速吃满显存,且存在极大的内存碎片,导致吞吐量极低。
为了解决这个问题,我引入了 vLLM 框架,并深入应用了它的 PagedAttention 机制。它的核心实现原理借用了操作系统中‘虚拟内存分页’的思想 :
打散与分页:传统的注意力机制需要把一个请求的 KV Cache 存放在连续的物理显存中。PagedAttention 将 KV Cache 切分成固定大小的块(Blocks/Pages) 。
动态映射:它维护了一个类似页表的结构,将逻辑上连续的 Token 映射到物理显存中离散的页上。这样不仅将显存碎片率降到了极低,还允许动态增长 。
Continuous Batching(连续批处理):配合分页管理,我们不再需要等待整个 Batch 里最长的那条代码生成完毕。只要有请求结束释放了显存页,新的请求就能立刻插进来(细粒度调度),极大提升了 GPU 利用率 。
总结亮点: 除了部署 vLLM,我们这个项目的杀手锏在于:我们将 PagedAttention 的长上下文管理能力,与我们自己做的 Jacobi 一致性蒸馏(JCD)结合在了一起 。我们让蒸馏后的模型学习并行解码的收敛分布,在 vLLM 的后端上实现了单步增量解码,最终让系统的推理速度飙升到了 83.58 samples/s,而准确率几乎没有损耗 。”
4. LoRA微调的原理是什么?Rank (r) 和 Alpha ($\alpha$) 是如何设置的,理由是什么?
【面试官视角】: 他想甄别你是真正理解了“低秩本征空间”的数学原理,还是仅仅在 LLaMA-Factory 的界面上盲目地调参。
【答题话术建议】:
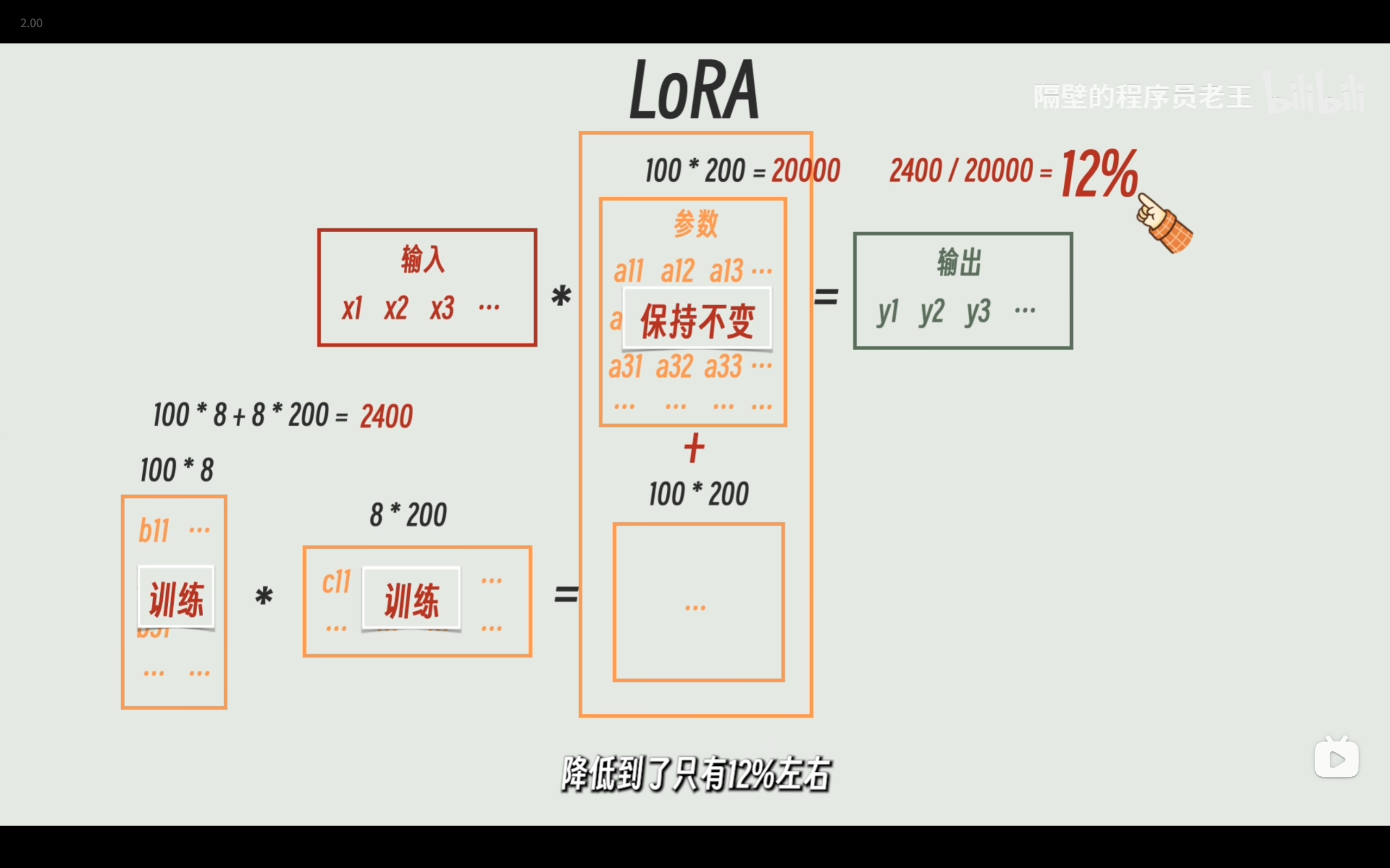
“关于 LoRA 的原理,它的核心思想可以用一句话概括:‘大模型的参数虽然极其庞大,但它们在特定下游任务上的学习更新,其实发生在一个内在的低维度空间里(低秩)。’
因此,我们在微调时,冻结住原始基座模型的所有权重 ($W_0$),在旁边旁路增加两个降维和升维的可训练矩阵($A$ 和 $B$)。前向传播时,原本的输出变成了 $h = W_0x + BAx$。这样我们只需要训练极少量的参数($A$ 和 $B$),就能达到全量微调(Full Fine-Tuning)相近的效果,极大节省了显存。
在我们的项目中,关于参数的设置我是这样考量的:
关于 Rank ($r$) 的设置: $r$ 决定了这两个矩阵的中间维度(也就是秩)。
常规场景: 如果只是让模型学个语气或者做简单的指令对齐(比如变成客服),$r$ 设置为 8 甚至 4 就足够了。
我们项目的理由: 但在我的项目中,大模型需要学习两样非常硬核的东西:一个是网安领域的专业知识库,另一个是严谨的 VSDL 脚本语法规范。 这涉及深层的逻辑和知识注入,低秩空间太小会发生信息瓶颈。因此我经过对比实验,将 $r$ 设置得相对较高(通常在 16 到 32 之间),在这个数值下,模型既能有效记住 VSDL 的语法规则,又不会引入过多的参数导致过拟合。
关于 Alpha ($\alpha$) 的设置: $\alpha$ 是一个缩放因子(Scaling Factor)。
在 LoRA 的公式中,旁路矩阵的输出会乘以 $\frac{\alpha}{r}$ 然后加到原权重上。
设置理由: 业界的一个标准工程经验是将 $\alpha$ 设置为 $r$ 的两倍(比如 $r=16, \alpha=32$)或者与 $r$ 保持一致。我通常采用 $\alpha = 2r$。这样做的数学直觉是:当我们在调参时改变 $r$ 的大小,$\frac{\alpha}{r}$ 的比例保持不变,这保证了 LoRA 旁路的梯度更新幅度与原模型权重的量级保持相对稳定,不需要每次改了 $r$ 就去重新痛苦地调整 Learning Rate(学习率)。
【总结亮点】: 这样回答,你不仅讲清楚了公式 ($W_0 + BA$),还说出了 $r$ 和业务复杂度的关系,以及 $\alpha$ 在工程上稳定梯度的作用,完美展现了你的算法体感(Intuition)。
5. 推荐系统是怎么设计的?知识图谱(KG)在里面的作用是什么?
【面试官视角】: 面试官想知道你为什么不用传统的推荐算法(比如协同过滤),而是大费周章去搞知识图谱。你需要凸显出教育/网安场景的特殊性。
【答题话术建议】:
“针对我们平台的推荐系统,我放弃了传统的协同过滤(Collaborative Filtering)等主流推荐算法,而是采用了基于知识图谱(KG)和图神经网络(GNN)的架构。
知识图谱在这里扮演了‘大脑逻辑地图’的作用,它的核心价值是为了解决两个传统算法无法解决的痛点:
解决‘冷启动’与‘数据稀疏’问题: 传统算法是基于‘用户相似度’的(比如张三和李四都看了 A 题,所以把 B 题也推给李四)。但教育平台天然数据稀疏,一个新生刚进来,根本没有交互历史。而知识图谱里固化了专家经验(比如‘SQL注入’是‘数据库提权’的前置条件)。即便学生是新来的,只要他在这一个前置节点上做错了,系统立刻就能顺着图谱的边(Relation),精准推荐基础理论课程。
打破‘信息茧房’,实现严格的前置依赖推荐: 学习和买东西不一样,买东西推荐相似商品就行,但学习有严格的拓扑依赖。如果学生不会‘计算机网络’,强行推荐‘跨站脚本攻击(XSS)’毫无意义。
具体的设计与落地路线是这样的:
第一步(图构建): 我使用 Neo4j 搭建了底层图谱,里面包含了三类实体节点:‘学生’、‘知识点/能力标签’、‘靶场课程资源’。
第二步(图嵌入与特征提取): 我使用了 TransE 算法,将这些实体和关系(比如 Student-Mastered->Knowledge)映射到低维向量空间。为了让表示更丰富,我还会把大模型提取的文本特征(Text Embedding)融入进去。
第三步(GNN 推荐): 将这些 Embedding 喂给图神经网络(GNN)。GNN 通过消息传递机制(Message Passing),可以把一个学生周围关联的‘未掌握知识点’和‘适合的靶场资源’进行聚合打分。
最终结果: 比如大模型在上一环节判定某个学生‘静态盐值配置错误’,GNN 就会在图谱中定位到这个知识点,向外跳跃(Multi-hop),计算出当前最适合填补他这个漏洞的靶场实验,从而实现了从‘静态分析漏洞’到‘动态推送学习路径’的完整闭环。
【总结亮点】: 这段话清晰地勾勒了‘为什么不用传统算法 $\rightarrow$ KG 的核心优势(逻辑依赖) $\rightarrow$ TransE+GNN 的落地 Pipeline’。这证明了你具备从 0 到 1 架构复杂 AI 应用的能力,而不是只会调 API。
- wechat
- alipay

