
A Comprehensive Survey of World Models
1.《Understanding World or Predicting Future? A Comprehensive Survey of World Models》
这是一篇关于世界模型的综述,提出一种关于世界模型的系统性分类:理解世界、预测未来。本文首先强调世界模型在1)构建内部表征以理解世界的机制2)预测未来状态以模拟和指导决策两种分类的现态,然后探索世界模型在关键领域的应用,包括自动驾驶、机器人技术、社会模拟等,最后指出关键挑战并提供未来可能的研究方向的分析。
1.1 概述
本文将构建世界模型分为两个主要分支:内部表征和未来预测。
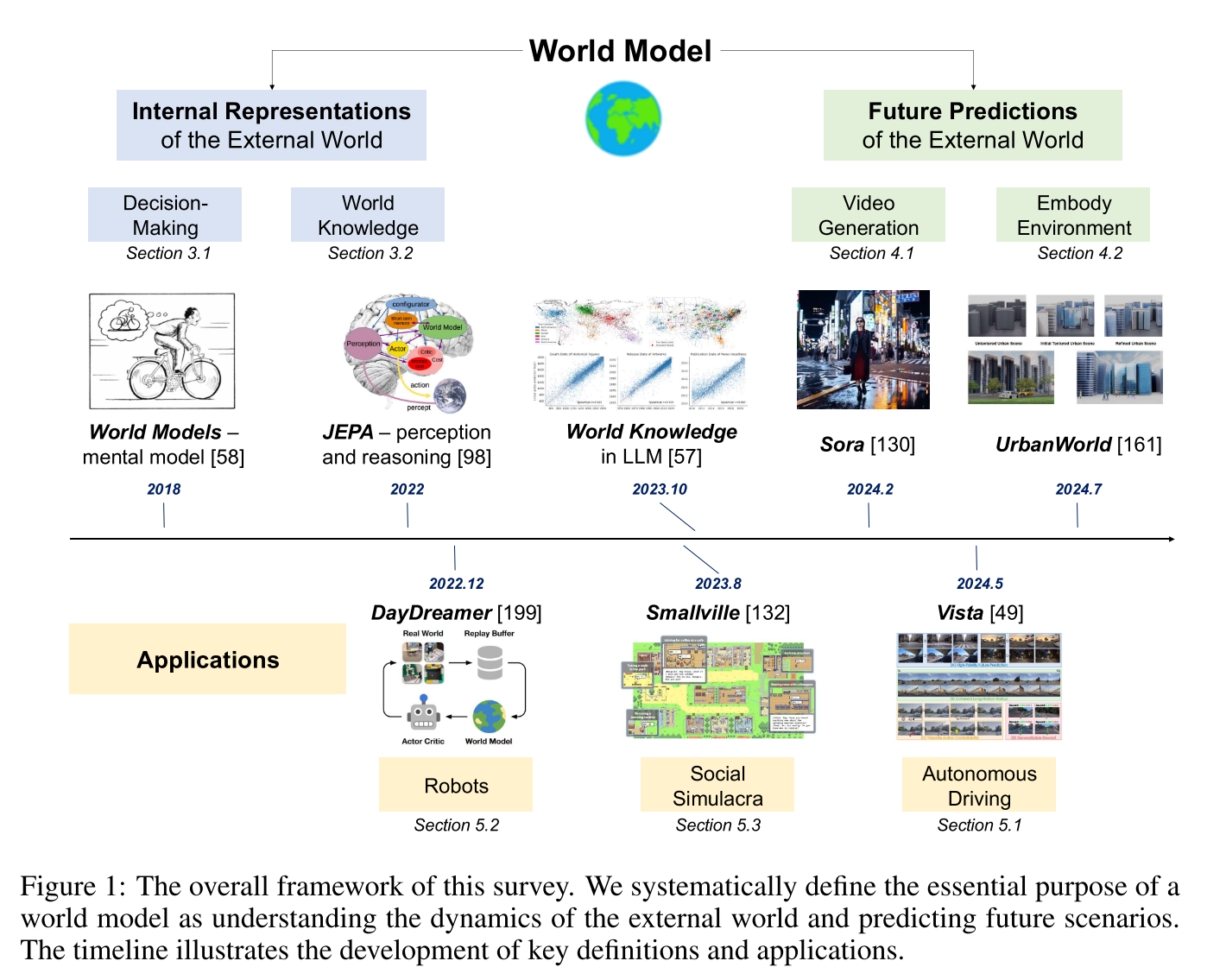
- 针对世界模型提出一种新颖的分类系统,紧紧围绕两大功能:1)构建隐式表征,以理解外部世界的机制2)预测外部世界的未来状态。第一类侧重于开发学习和内化世界知识以支持后续决策的模型,而第二类则强调从视觉感知增强对物理世界的预测和模拟能力。
- 提出世界模型在自动驾驶、机器人技术、社会模拟等不同领域的关键应用
- 重点介绍了能够适应更广泛实际应用的世界模型的未来研究方向和趋势
世界模型的发展
世界模型的灵感来自于心理学上的“心智模型”,Ha等人在2018年正式提出世界模型,该模型受到人类认知系统的启发,能够通过与环境的交互学习并模拟潜在的未来世界状态。
随后Yann LeCun在2022年提出联合嵌入预测架构(Joint-Embedding Predictive Architecture,JEPA),该架构中的预测器可以看作是一个原始的世界模型,使用抽象的预测目标,消除不必要的像素级细节,从而使模型学习到更多语义特征。
2023年以来大语言模型展现出的潜在世界认知,包括空间和时间理解以及构建认知地图的能力,使其能够预测现实世界的场景。
OpenAI在2024年发布的Sora模型被认为是世界模拟器的视频生成模型,能够输入真实世界的视觉数据并生成预测未来世界演变的视频。
无论是学习外部世界的内部表征还是模拟其运行原理,世界模型的根本目的是理解世界动态并预测未来场景。
1.2 外部世界的内在表征
1.2.1 世界模型在决策中的应用
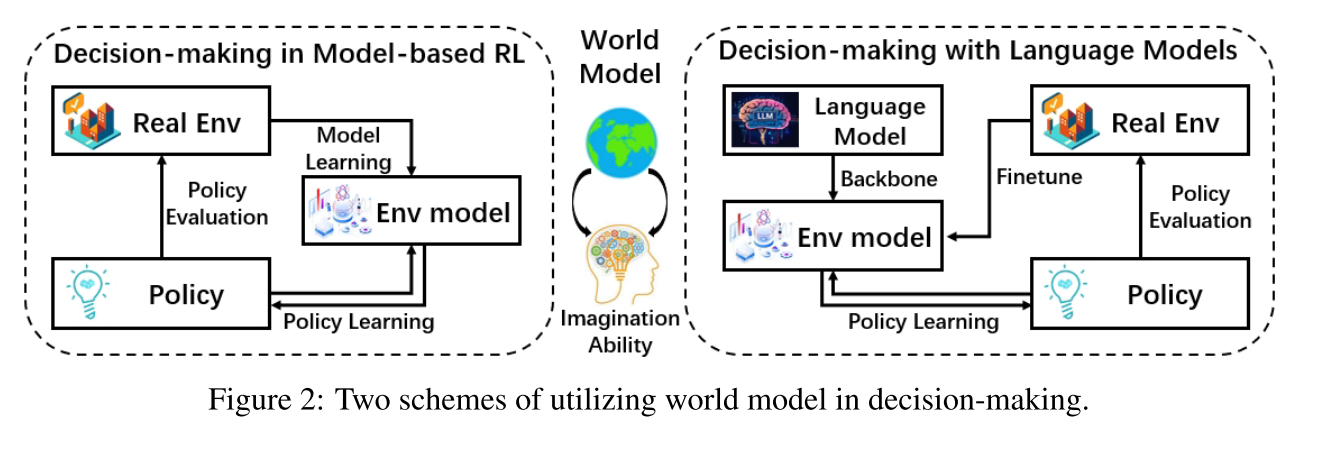
在决策任务中,理解环境是优化策略生成的主要任务。因此,决策中的世界模型应该包含对环境的全面理解。它使我们能够在不影响真实环境的情况下采取假设行动,从而降低试错成本。
如何学习和利用世界模型的研究最初是在基于模型的强化学习领域提出的。此外,LLM 和 MLLM 的最新进展也为世界模型的构建提供了全面的支撑,由于语言是一种更通用的表示形式,基于语言的世界模型可以应用于更泛化的任务。
- 基于模型的强化学习(Model-based Reinforcement Learning, MBRL)
学习世界模型
在基于模型的强化学习中,世界模型指的是环境的模型,通常用一个元组 ⟨S,A,M,R,γ⟩ 表示,其中 S 是状态空间,A 是动作空间,M 是状态转移函数,R 是奖励函数,γ 是折扣因子。学习世界模型的目标是预测环境的动态特性,以便更好地进行决策。

最直接的方法是最小化单步预测的均方误差(公式1),为了进一步建模不确定性,特别是随机性引起的不确定性,Chua等人提出了利用概率性的转移模型,并通过最小化真实转移和预测转移之间的KL散度(公式 2)来学习。
基于世界模型生成策略

利用学习到的世界模型规划最优的动作序列,最直接的办法是通过模型预测控制(MPC),即在每个时间步,通过前瞻一定的时间步长$\tau$,采样可能的动作序列,并选择能够最大化未来奖励的动作(公式 3)。
- 以语言主干的世界模型
利用LLM和MLLM构建基于语言的世界模型进行决策任务。
通过LLM直接生成动作的世界模型
LLM具有强大的推理能力,可以直接基于构建的世界模型生成决策任务所需的动作
【例如,在导航场景中,研究者利用预训练的文本到视频模型进行机器人控制,并使用LLM的输出来标注机器人操作的文本指令。还有研究通过分解视频生成过程来学习组合式的世界模型,这种方法在未见过的任务上表现出强大的少样本迁移能力。】
模块化使用使用LLM的世界模型
将LLM作为模块与传统规划算法结合,进一步提升决策质量。
【例如,有研究将具身智能体部署在虚拟环境的模拟器中,并将相应的具身知识注入LLM,然后利用蒙特卡洛树搜索(MCTS)来寻找真实的具身任务目标。】
1.2.2 被模型学到的世界知识
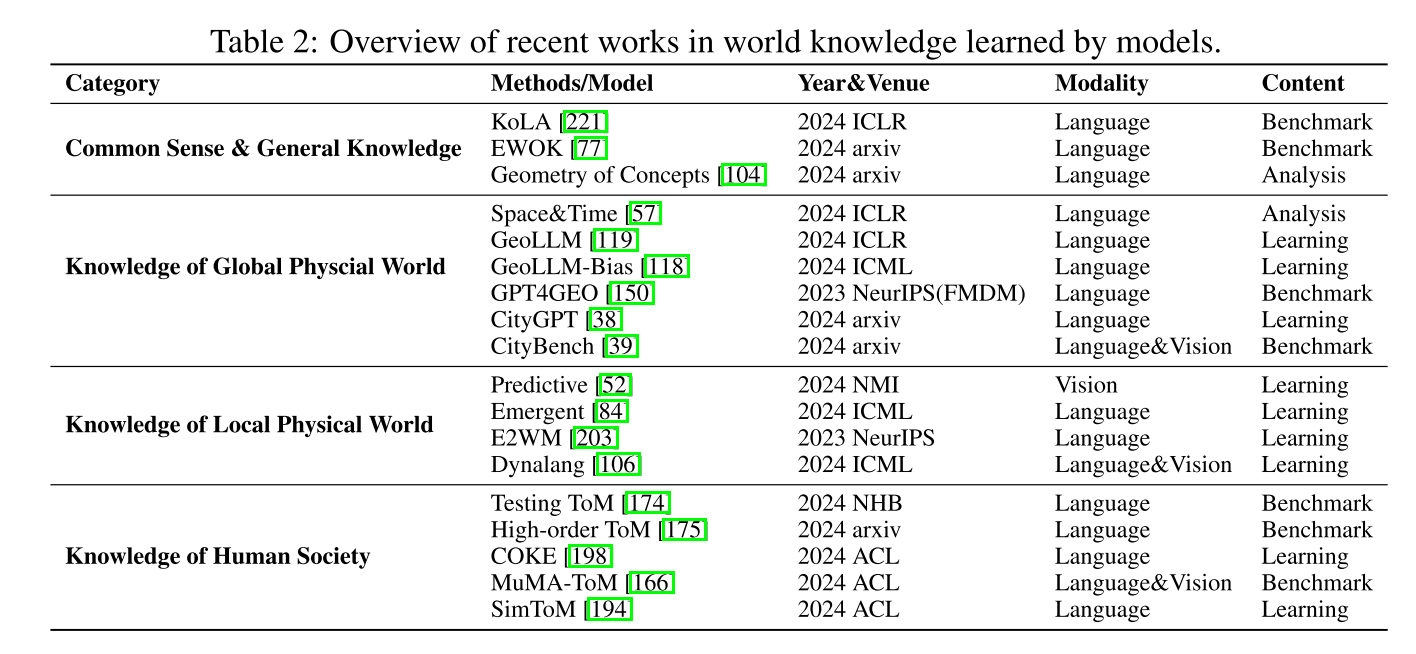
全球物理世界的知识:LLM可能不仅仅是收集表面统计信息,而是真正习得了关于世界的空间和时间知识。
局部物理世界的知识:理解人类日常生活和大多数现实世界任务的主要环境。
人类社会的知识:LLM对人类社会模式的理解,对社会规则和隐含知识的理解。
1.3 物理世界未来的预测
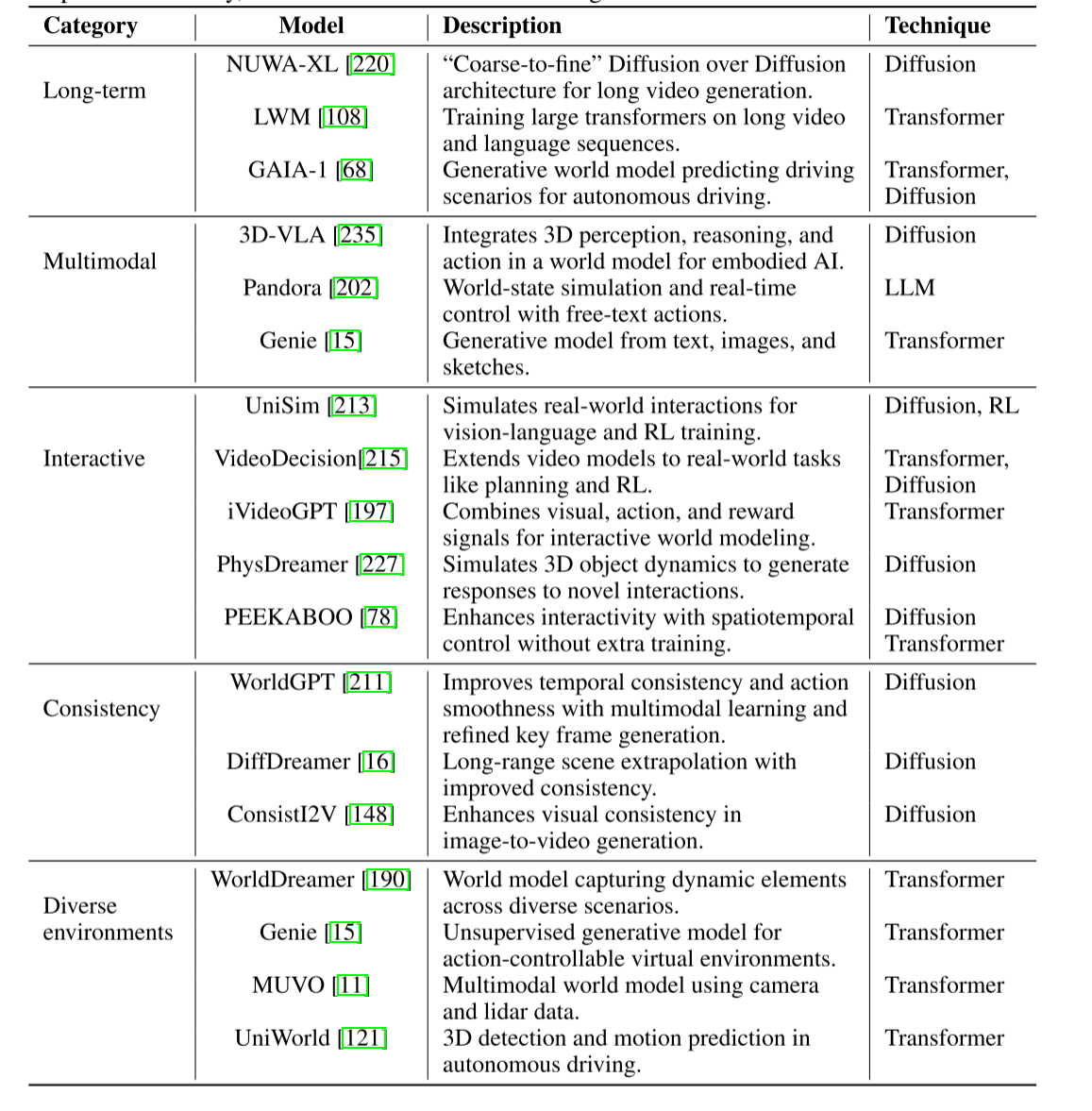
1.3.1 作为视频生成的世界模型
视频世界模型是一种计算框架,旨在通过处理对过去的观察和潜在的动作,在视觉环境中模拟和预测世界的未来状态。
Sora是视频世界模型的一个突出例子,它能够根据文本、图像和视频等多种输入模态生成高质量、时间上连贯的、长达一分钟的视频序列,这些特性表明 Sora 有潜力作为世界模拟器,根据对初始条件和模拟参数的理解来预测世界的未来状态。
但是Sora存在两个局限:1)因果推理,模型在模拟环境中动态交互不足,只能基于观察到的初始状态被动地生成视频序列,而不能主动干预或预测动作变化如何改变事件进程。2)不能始终如一地再现正确的物理规律,准确模拟真实世界的物理现象存在困难。
视频世界模型应该具有以下能力:长期预测、多模态、可交互、一致性、不同环境
1.3.2 作为具身环境的世界模型
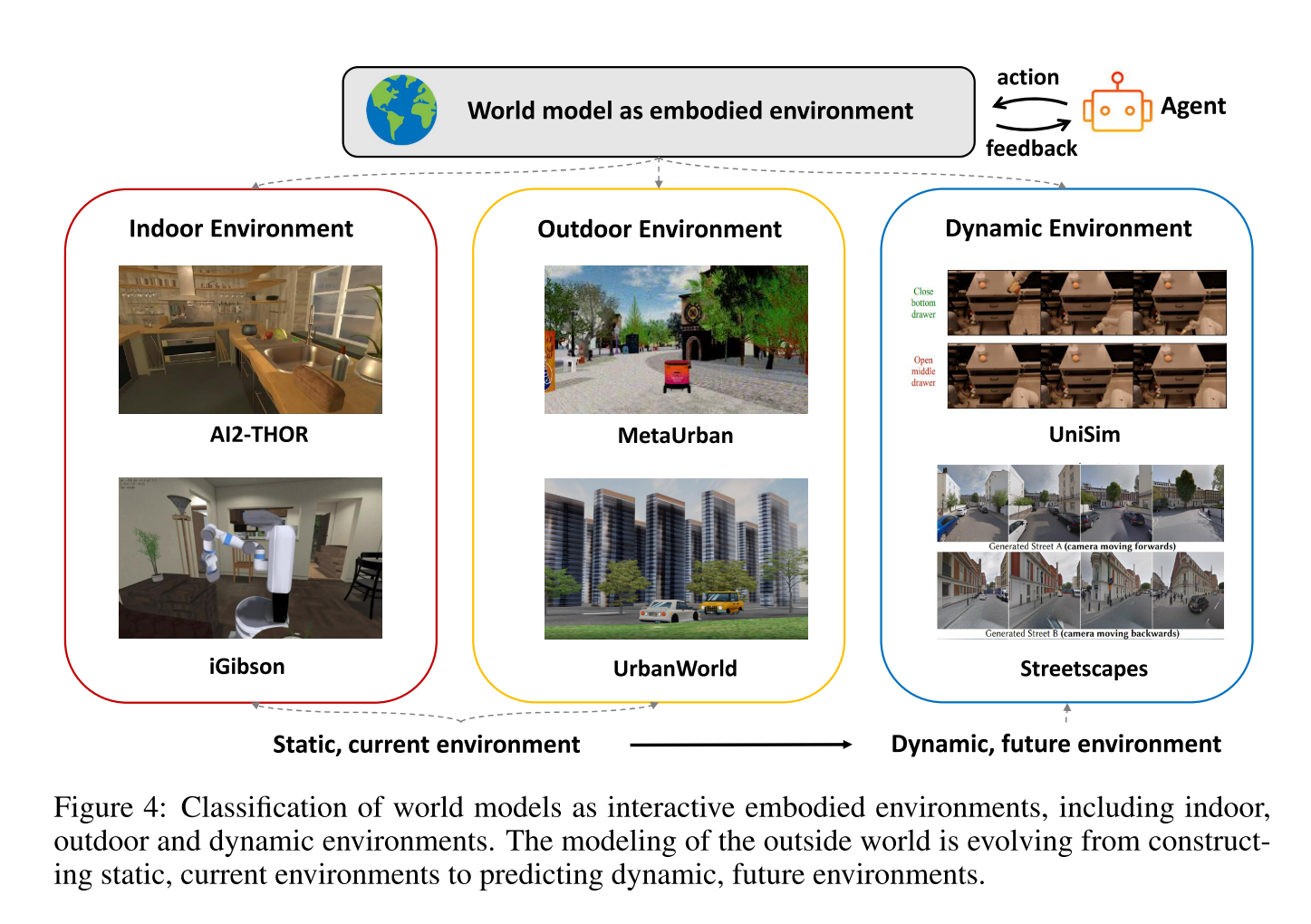
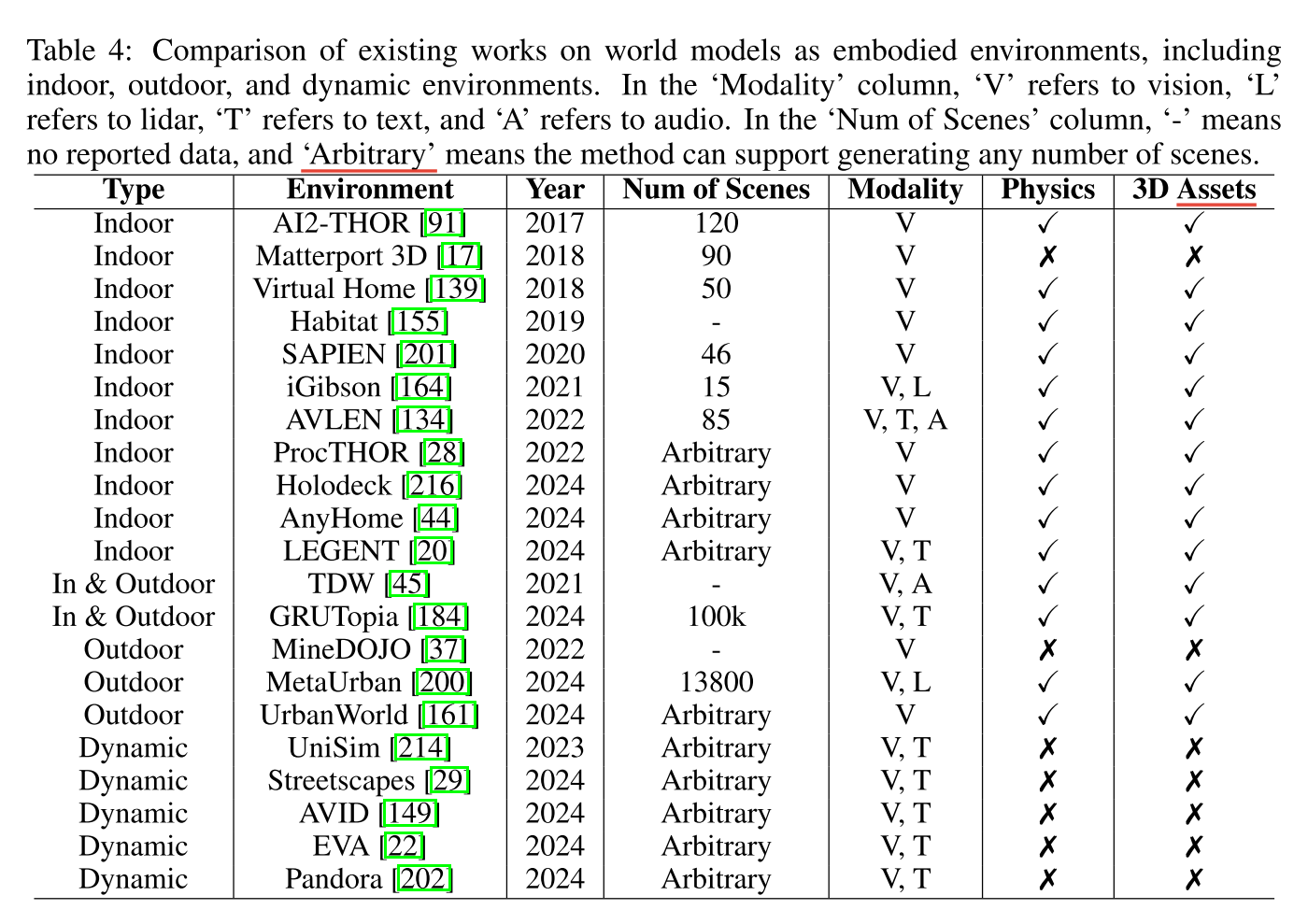
这部分重点在于模拟和预测智能体如何与外部世界互动和适应,文章将这类世界模型分为室内、室外和动态环境三个类别
室内环境:提供可控、结构化的场景,智能体可以执行细致的、特定于任务的动作,如物体操作、导航和与用户的实时交互。
室外环境:更大规模、更高可变性的室外环境,如城市环境中的导航
动态环境:使用生成世界模型创建灵活的动态环境,使智能体能够体验多样化的第一人称视角。
作为具身环境的世界模型从静态到动态,使智能体能够更好地适应未见过的条件,增强其在现实世界任务中的泛化能力。
1.4 应用
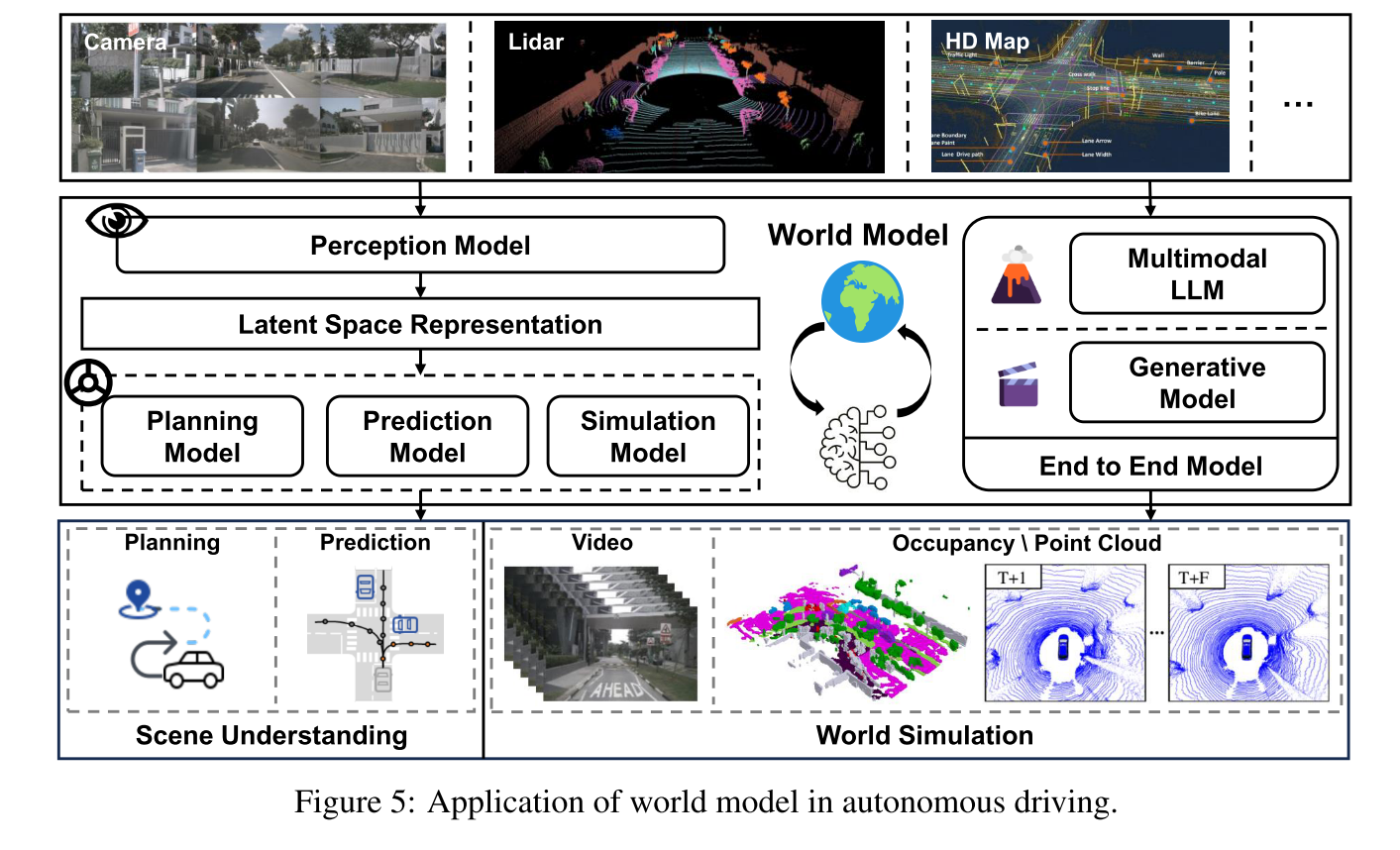
1.4.1 自动驾驶
基于视觉的生成模型和多模态大型语言模型的快速发展,使得作为理解世界状态和预测未来趋势的世界模型,在自动驾驶领域受到越来越多的关注。
1.4.2 社会模拟

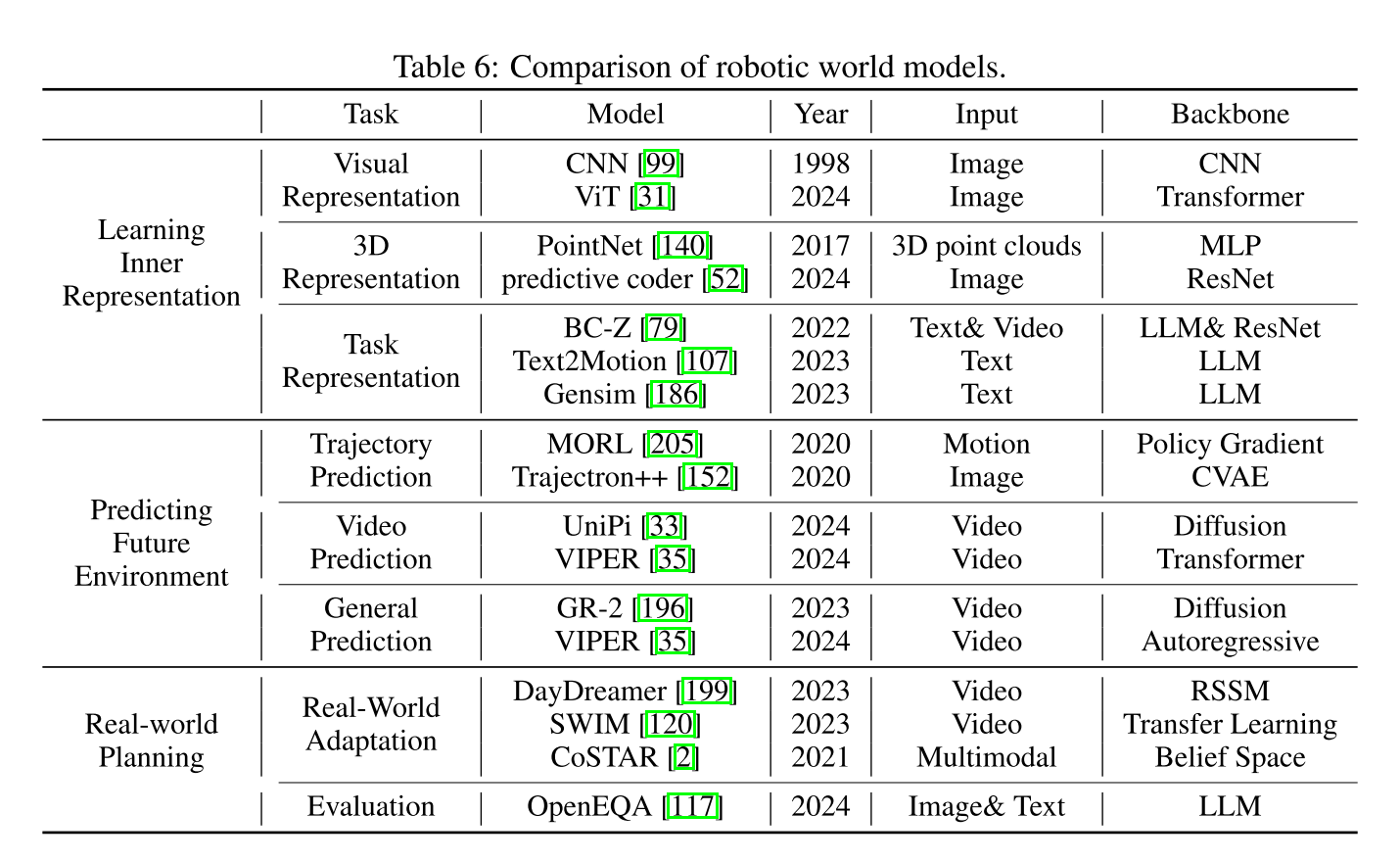
1.4.3 机器人技术
世界模型使机器人能够在复杂环境中有效地感知、预测和执行任务。
大型语言模型(LLM)和世界模型被认为是通往通用人工智能(AGI)的可能路径之一,因为它们可以作为机器理解世界基本规律的起点。
1.5 我的想法
本文对世界模型进行了全面的综述,系统地探讨了它们的两个主要功能:对外部世界的隐式表征和未来预测。研究者强调了决策中的世界模型、模型学习的世界知识、作为视频生成的世界模型以及作为具身环境的世界模型。概括了世界模型在自动驾驶、机器人技术和社会模拟等关键应用领域的进展。最后,重点介绍了一些开放性问题,并提出了有前景的研究方向。
这篇文章对于理解世界模型有一定帮助,读完后我认为世界模型是理解世界动态并预测未来场景,通过对外部世界的隐式表征理解世界,通过对过去的观察和潜在的动作来模拟和预测未来。针对文章我想提出几个疑问:1)世界模型的范围如此广阔,既有基于模型的强化学习方法进行决策,又有基于LLM和MLLM的世界模型,既有Transformer方法生成预测序列,又有Diffussion方法生成视频,我应该从何下手对世界模型进行攻击呢?我最直观的想法是将攻击细化到某一种世界模型的某一个组件,比如针对基于MLLM的世界模型中MLLM的预训练编码器,针对Dreamer世界模型对图像做分割、刚性变换、合成、物理重现【AdvDreamer】,又比如针对基于LLM的世界模型采取常规的LLM攻击方式,但是这些攻击都没有脱离已有的攻击范式,只是更换了攻击场景【就像针对预训练编码器的攻击可以同时运用在LLM和MLLM中】,似乎缺乏创新。目前在2D图像领域攻击的研究已经很多了,我们是否可以向3D世界转换【AdvDreamer】【Point Cloud】2)这篇文章提出了非常多的方法,读完后仍然存在非常多的疑问,我目前大致了解世界模型的系统性分类和主要应用,但是对世界模型的主流框架仍然不清晰【既然世界模型需要处理多模态的输入,就涉及到文本编码和图像编码的相关内容,是否可以从核心组件对世界模型进行攻击,这样的攻击是否更具有普适性】,我觉得应该细化到某一个具体的场景,再去理清这个场景下世界模型的结构,否则在如此庞大的知识网络中探索有一点摸不到重点。
2.《Self-Supervised Learning from Images with a Joint-Embedding Predictive Architecture》
Meta 首席人工智能科学家 Yann LeCun 提出了一种新的架构JEPA,通过联合嵌入预测架构,在自监督学习中实现了高效、高语义的表征学习。AI at MetA

2.1 概述
自监督学习的两大主流方法:基于不变性的方法、生成式方法。
基于不变性的方法【如对比学习,构造正样本对和负样本对,让模型学习相似于不相似的表征】,旨在优化一个编码器,它可以生成同一张图片多个视角的相似的嵌入,这些视角是由人工精心设计的数据增强【随即缩放、剪裁、颜色抖动】实现的。
基于生成式的方法【如MAE,Masked Autoencoder,基于遮掩重建的自监督学习方法,遮掩图片的一部分并重建该部分,属于像素层的重建】,通过重建被遮掩的像素或标记来学习特征。
基于不变性的方法需要人工设计数据增强,且可能引入任务无关的偏置【数据增强的先验是这些变化不会改变图片的语义,这种假设可能引入任务无关的偏置,如过于强调颜色不变性使得模型忽略纹理或形状信息】,基于生成式的方法学到的特征偏向底层细节,语义抽象能力较弱。
本文提出一种联合嵌入预测架构JEPA,不需要手工设计数据加强,且从嵌入空间及进行预测,而非像素空间,使得模型学到更抽象的表示。
2.2 核心算法
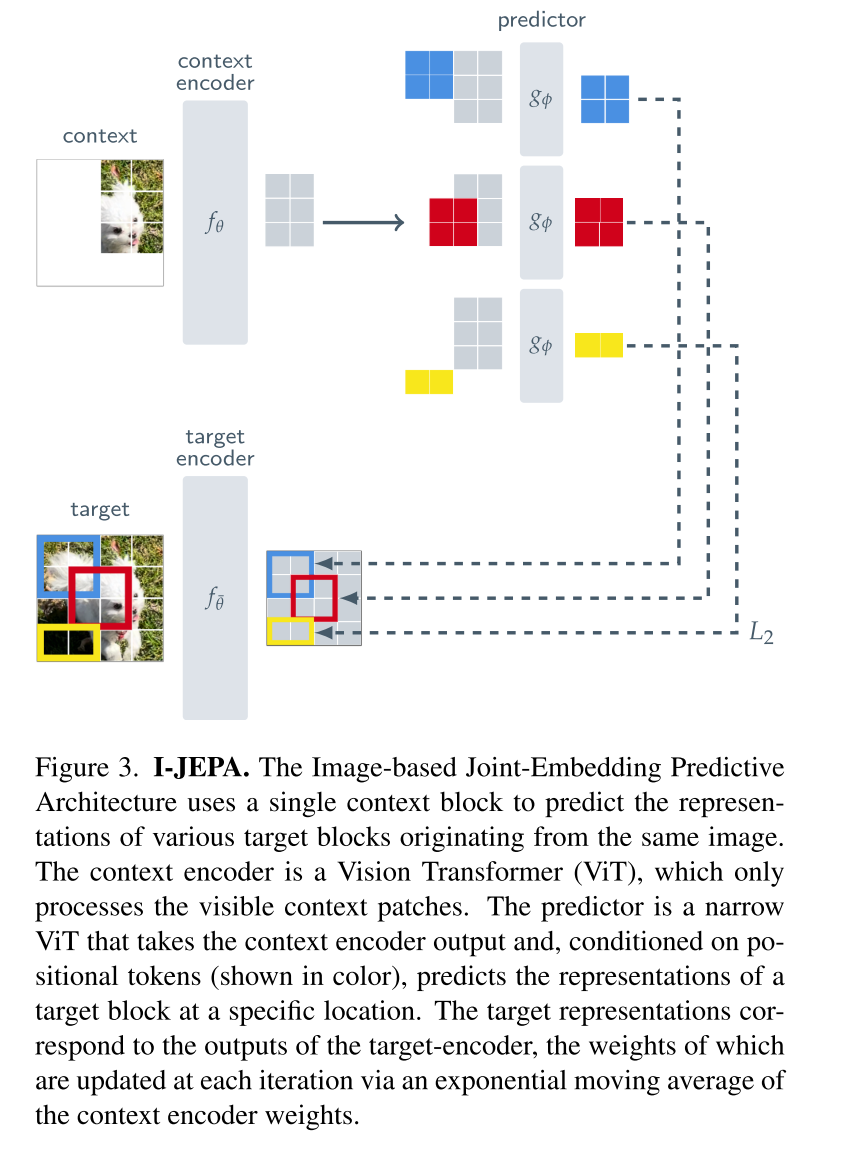
JEPA从单个上下文块(context block)预测同一图像中多个目标块(target block)的表示,通过在嵌入空间预测而非像素空间,引导模型学习抽象语义特征。
JEPA的三个核心组件分别为文本编码器、预测器、目标编码器,它们都是使用Vison Transformer【ViT】架构。
- context encoder
文本编码器用于处理上下文块,生成上下文块的嵌入。
- target encoder
目标编码器用于生成目标块的嵌入,参数通过上下文编码器的指数移动平均更新【EMA,Exponential Moving Average,一种平滑参数更新策略,目标编码器参数变化缓慢,避免与上下文编码器同步快速更新导致模型崩溃】(不太懂具体细节,我理解为一种更平滑的参数更新方法)
- predictor
预测器是基于上下文嵌入和位置标记,预测目标块的嵌入。
- loss
预测嵌入与目标嵌入的L2距离,优化上下文编码器和预测器参数,目标编码器通过EMA更新。
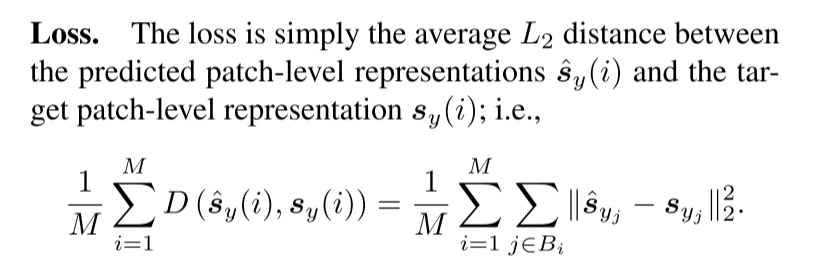
2.3 我的想法
JEPA的核心思想非常简洁,通过精心设计上下文块和目标块,使用ViT的架构设计了文本编码器、目标编码器和预测器,通过减少预测器的表征与目标编码器的表征之间的差异,从嵌入空间而非像素空间的层面学习更抽象的表征。优点是不用精心构建数据增强,减少无关任务偏置的引入【基于不变性方法】,同时从嵌入空间而非像素空间学习到更抽象的语义【基于生成式】。
第一篇综述文章将JEPA架构归为世界模型的类别,世界模型旨在学习外部世界抽象的内在表征,通过对过去的观察和潜在的动作来模拟和预测未来,与JEPA从单个上下文块预测同一图像中多个目标块的表示,学习抽象语义特征表示非常相似。
JEPA的核心部分是采用ViT架构,如果需要针对JEPA攻击可以从ViT的脆弱性入手,由于没有确定世界模型的具体攻击方向,所以阅读本文旨在深入对世界模型的认知。
3.ViT
ViT 通过将图像视为序列并利用 Transformer 的全局建模能力,核心思想如下图
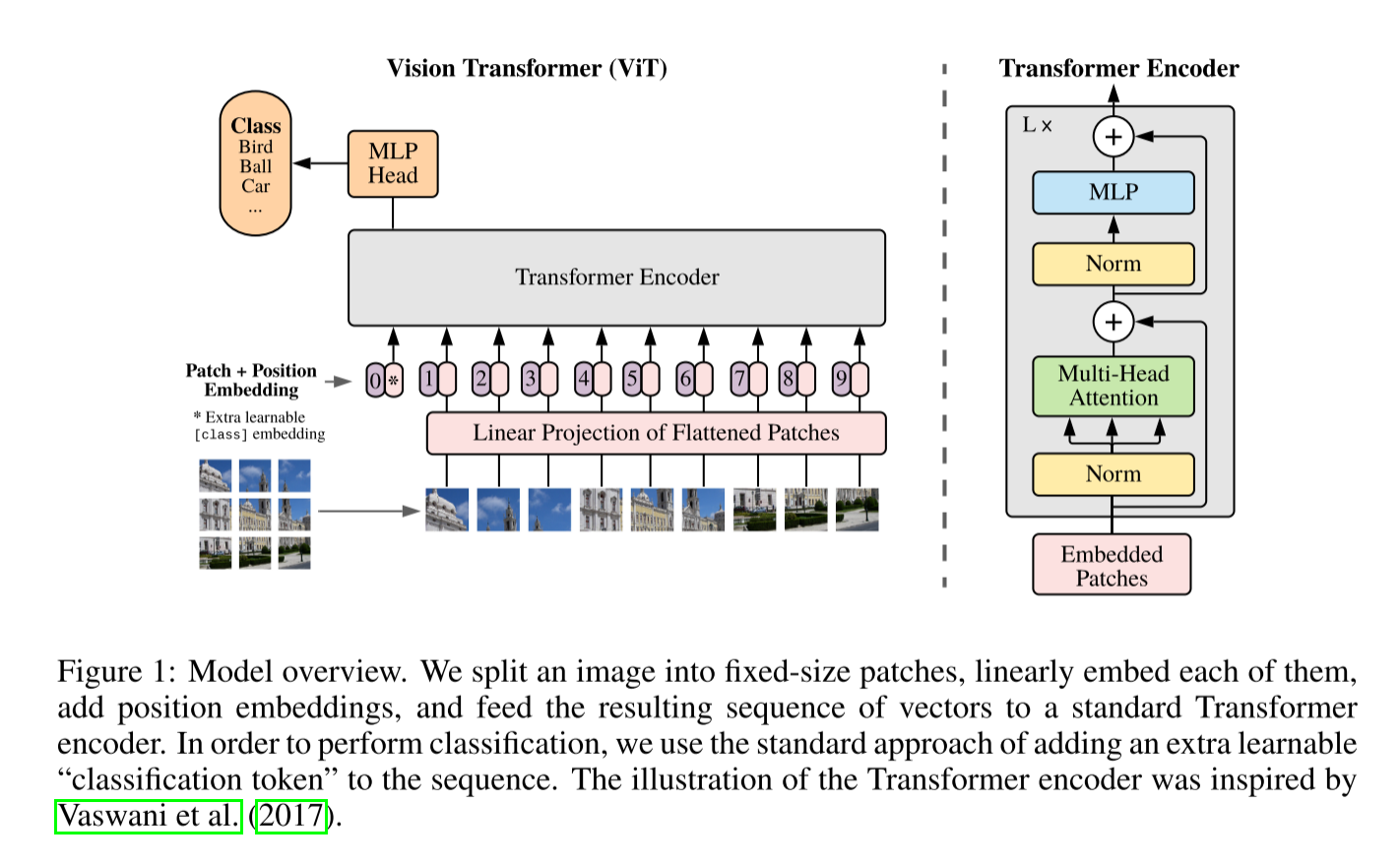
由于JEPA中的核心组件是使用ViT架构,所以尝试跑ViT-pytorch以了解ViT的原理。我没有细看论文,对ViT大致理解为将图片分割成小的Patch,将每一个Patch加上对应的位置信息,再经过Transformer编码器得到高维的嵌入,最后接一个全连接层的头部,输出类别的置信度分数,而JEPA正是在嵌入空间预测,以学习图像抽象的语义表征。
在Github上找到Vit-pytorch,该项目是对ViT的简单实现,配置好环境后便可以在一个伪图片上【256x256图片,像素点随机生成】验证。
首先我想在一张真实的图片上验证,最终可以实现在输入一张图片后得到该图片的类别,效果如下。测试图片为dog,预测分类id为 216【ViT的训练数据集是ImageNet-1000,其中id为216的是clumber(拳师犬)】,由此可见在简单测试是可以通过的。
后来我想在CIFA-10上做分类任务,想利用ViT模型处理图片并实现分类任务。下面是训练的过程,最好的模型权重保留在checkpoint文件夹下。最后使用训练好的模型权重实现在CIFA-10上的分类任务。
与传统的CNN不同,ViT将 Transformer 架构(原用于 NLP 任务)迁移到计算机视觉任务中,直接通过自注意力机制处理图像数据。
以上代码是由Gpt-4o-min生成,我只了解整个流程的大致过程,仍有很多细节没有处理,在跑代码的过程中遇到多进程运行错误问题,通过将worknum的数量改小解决【本地推理速度实在太慢了,后来租了一台云服务器,正在使用中】
4.Adversarial Example Generation
项目地址 https://docs.pytorch.org/tutorials/beginner/fgsm_tutorial.html
FGSM 是一种简单而有效的白盒对抗攻击方法,属于无目标攻击。它的核心思想是利用模型损失函数相对于输入数据的梯度信息,通过在梯度方向上施加微小的扰动,使得模型对被扰动后的输入产生错误的分类结果。

4.1 核心算法

4.2 实验结果
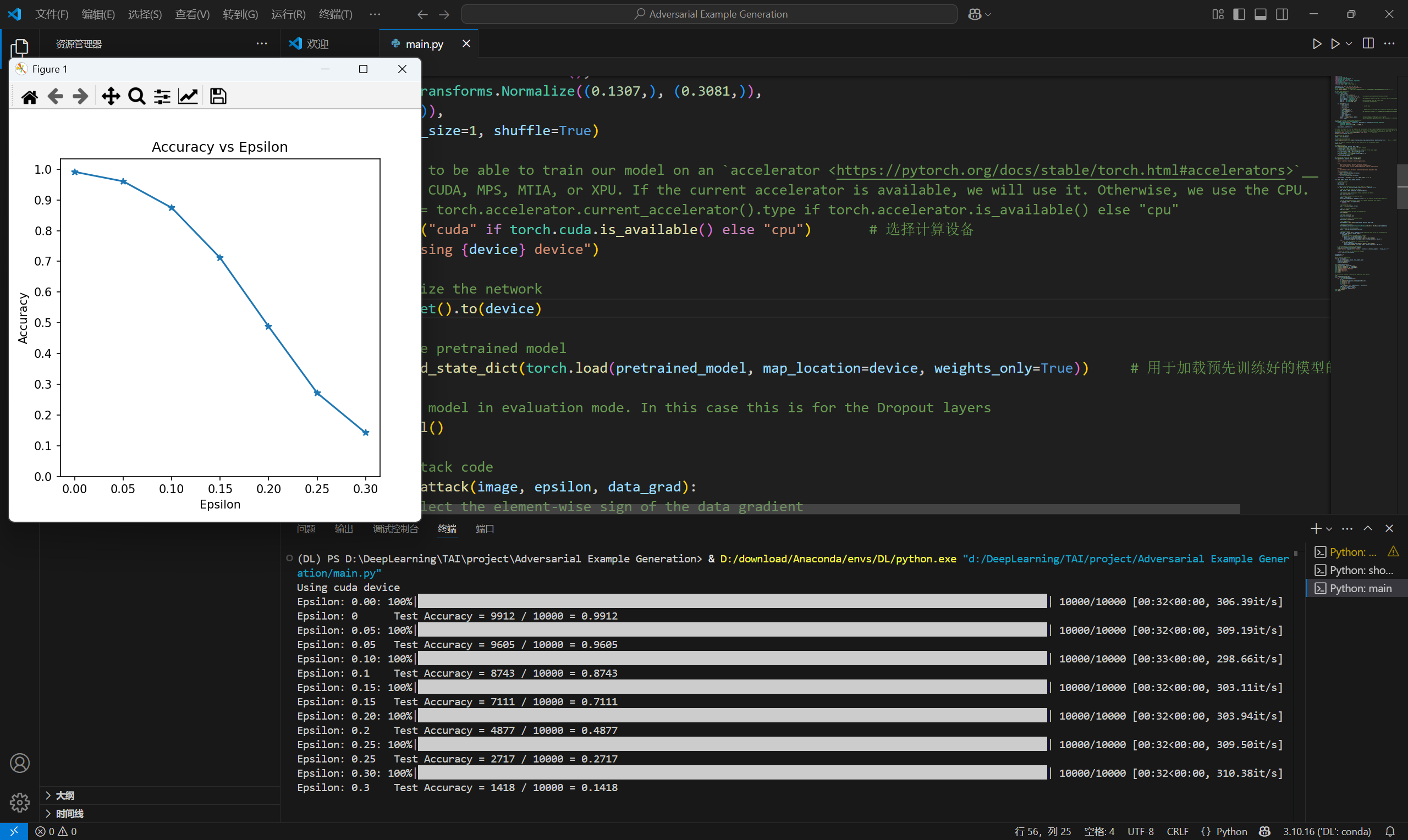

4.3 我的想法
FGSM是一种非常简单且易于理解的对抗攻击方法,针对上面的实验提出以下优化方向:1)数据集MNIST是灰度图像,通道数为1,能否实现输入为rgb图像将通道数变为3并对图像进行梯度攻击 2)实验的模型权重是下载下来直接使用的,能否自己训练模型得到模型权重
3)LeNet的网络结构非常简单,在手写数字数据集上使用CNN处理灰度图像,现在处理图像的方式有哪些【ViT】,针对这些方式的攻击又有哪些【PGD】【Patch-wise Attacks】【Attention-based Attacks】。
 wechat
wechat- alipay

