
Pytorch Tutorial
项目树
.
├── pycache/ [目录]
├── check_point/ [目录]
├── dataset/ [目录]
├── img/ [目录]
├── model.py [Python文件]
├── test.py [Python文件]
├── train_optimized.py [Python文件]
└── train.py [Python文件]
train.py
这是训练代码,基本流程为准备数据集->加载数据集->构建神经网络->定义损失函数->定义优化器->开始训练1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86import torchvision
from torch.utils.data import DataLoader
from torch import nn
import torch
from model import classify_model, vgg_16
# 定义设备
device = torch.device("cuda" if torch.cuda.is_available else "cpu")
print("当前设备 {}".format(device))
# 准备数据集
train_dataset = torchvision.datasets.CIFAR10("dataset",train=True,transform=torchvision.transforms.ToTensor(),download=True)
test_dataset = torchvision.datasets.CIFAR10("dataset",train=False,transform=torchvision.transforms.ToTensor(),download=True)
# 数据集长度
train_data_size = len(train_dataset)
test_data_size = len(test_dataset)
print("训练数据集的长度 {}".format(train_data_size))
print("测试数据集的长度 {}".format(test_data_size))
# 加载数据集
batch_size = 64
train_dataloader = DataLoader(train_dataset,batch_size=batch_size)
test_dataloader = DataLoader(test_dataset,batch_size=batch_size)
model_name = "vgg16_1" # vgg16 / classify_model
# model = classify_model() # 自定义神经网络
model = vgg_16() # 利用现有的网络
model.to(device)
print(model)
# 损失函数
loss_fn = nn.CrossEntropyLoss()
loss_fn.to(device)
# 优化器
learning_rate = 1e-2
optimizer = torch.optim.SGD(model.parameters(),lr=learning_rate)
# 设置网络参数
total_train_step = 0
total_test_step = 0
# 训练轮数
epoch = 100
for i in range(epoch):
print("-------第{}轮训练开始--------".format(i+1))
# 训练步骤开始
model.train() # 只对特定层起作用,如Dropout
for data in train_dataloader:
imgs, targets = data
imgs = imgs.to(device)
targets = targets.to(device)
output = model(imgs)
loss = loss_fn(output, targets)
# 优化器优化模型
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_train_step = total_train_step + 1
if(total_train_step % 100 == 0):
print("训练次数 {},Loss: {}".format(total_train_step, loss.item()))
# 测试步骤开始
total_test_loss = 0
total_test_acc = 0
model.eval()
with torch.no_grad():
for data in test_dataloader:
imgs, targets = data
imgs = imgs.to(device)
targets = targets.to(device)
output = model(imgs)
loss = loss_fn(output, targets)
total_test_loss = total_test_loss + loss.item()
acc = (output.argmax(1) == targets).sum()
total_test_acc = total_test_acc + acc
print("整体测试集上的Loss: {}".format(total_test_loss))
print("整体测试集上的Acc: {}".format(total_test_acc/test_data_size))
torch.save(model.state_dict(), "./check_point/{}/classify_model_{}.pth".format((model_name), (i+1)))
print("模型已保存")
model.py
这是模型架构,定义了模型的结构1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33from torch import nn
import torchvision
# 搭建自定义神经网络
class classify_model(nn.Module):
def __init__(self):
super(classify_model, self).__init__()
self.model = nn.Sequential(
nn.Conv2d(3, 32, 5, 1, 2),
nn.MaxPool2d(2),
nn.Conv2d(32, 32, 5, 1, 2),
nn.MaxPool2d(2),
nn.Conv2d(32, 64, 5, 1, 2),
nn.MaxPool2d(2),
nn.Flatten(),
nn.Linear(1024, 64),
nn.Linear(64, 10)
)
def forward(self, x):
x = self.model(x)
return x
# 利用现有的网络,并修改
class vgg_16(nn.Module):
def __init__(self):
super(vgg_16, self).__init__()
self.model = torchvision.models.vgg16(weights=None)
self.model.classifier.add_module('add_Linear', nn.Linear(1000, 10))
def forward(self, x):
x = self.model(x)
return x
test.py
这是测试文件,测试训练后神经网络在分类任务上的效果1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46import torchvision
import torch
from PIL import Image
from model import classify_model,vgg_16
from torch import nn
# 定义CIFAR-10的类别标签
class_labels = [
"airplane",
"automobile",
"bird",
"cat",
"deer",
"dog",
"frog",
"horse",
"ship",
"truck"
]
image_path = 'img/cat1.jpg'
img = Image.open(image_path)
transforms = torchvision.transforms.Compose([torchvision.transforms.Resize((32,32)),
torchvision.transforms.ToTensor()])
img = transforms(img)
# 加载模型
model = vgg_16()
model.load_state_dict(torch.load("check_point/vgg16_1/classify_model_98.pth", weights_only=True))
# model = classify_model()
# model.load_state_dict(torch.load("check_point/classify_model/classify_model_20.pth", weights_only=True))
# print(model)
img = torch.reshape(img, (1, 3, 32, 32))
model.eval()
with torch.no_grad():
output = model(img)
pre_idx = torch.argmax(output, dim=1).item()
pre_label = class_labels[pre_idx]
confidence = torch.nn.functional.softmax(output, dim=1)[0][pre_idx].item()
print("预测标签为 {} ,置信度为 {}".format(pre_label, confidence))
train_optimized.py
这是优化后的训练代码1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172import torchvision
from torch.utils.data import DataLoader
from torch import nn
import torch
from model import classify_model, vgg_16
import matplotlib.pyplot as plt
import os
from tqdm import tqdm
# 定义设备
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
print(f"当前设备 {device}")
# 准备数据集
train_dataset = torchvision.datasets.CIFAR10(
"dataset",
train=True,
transform=torchvision.transforms.ToTensor(),
download=True
)
test_dataset = torchvision.datasets.CIFAR10(
"dataset",
train=False,
transform=torchvision.transforms.ToTensor(),
download=True
)
# 数据集长度
train_data_size = len(train_dataset)
test_data_size = len(test_dataset)
print(f"训练数据集的长度 {train_data_size}")
print(f"测试数据集的长度 {test_data_size}")
# 加载数据集
batch_size = 64
train_dataloader = DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
test_dataloader = DataLoader(test_dataset, batch_size=batch_size)
model_name = "vgg16_2"
# model = classify_model() # 自定义神经网络
model = vgg_16() # 利用现有的网络
model.to(device)
print(model)
# 损失函数
loss_fn = nn.CrossEntropyLoss()
loss_fn.to(device)
# 优化器
learning_rate = 1e-2
optimizer = torch.optim.SGD(model.parameters(), lr=learning_rate)
# 设置网络参数
total_train_step = 0
total_test_step = 0
epoch = 20
# 创建目录保存结果
os.makedirs("./check_point/", exist_ok=True)
os.makedirs(f"./check_point/{model_name}/", exist_ok=True)
# 初始化记录列表
train_losses = []
test_losses = []
test_accuracies = []
# 使用tqdm包装epoch循环
epoch_progress = tqdm(range(epoch), desc="总训练进度", position=0)
for i in epoch_progress:
epoch_progress.set_description(f"第 {i+1}/{epoch} 轮训练")
# 训练步骤
model.train()
epoch_train_loss = 0.0
# 使用tqdm包装训练批次循环
train_batch_progress = tqdm(train_dataloader, desc=f"训练批次", leave=False, position=1)
for data in train_batch_progress:
imgs, targets = data
imgs, targets = imgs.to(device), targets.to(device)
output = model(imgs)
loss = loss_fn(output, targets)
epoch_train_loss += loss.item()
optimizer.zero_grad()
loss.backward()
optimizer.step()
total_train_step += 1
# 更新批次进度条描述
train_batch_progress.set_postfix({"批次损失": f"{loss.item():.4f}"})
# 计算平均训练损失
avg_train_loss = epoch_train_loss / len(train_dataloader)
train_losses.append(avg_train_loss)
# 更新总进度条描述
epoch_progress.set_postfix({"训练损失": f"{avg_train_loss:.4f}"})
# 测试步骤
total_test_loss = 0.0
total_correct = 0
model.eval()
# 使用tqdm包装测试批次循环
test_batch_progress = tqdm(test_dataloader, desc="测试批次", leave=False, position=2)
with torch.no_grad():
for data in test_batch_progress:
imgs, targets = data
imgs, targets = imgs.to(device), targets.to(device)
output = model(imgs)
loss = loss_fn(output, targets)
total_test_loss += loss.item()
_, predicted = torch.max(output.data, 1)
total_correct += (predicted == targets).sum().item()
# 更新测试批次进度条描述
test_batch_progress.set_postfix({"测试损失": f"{loss.item():.4f}"})
# 计算测试指标
avg_test_loss = total_test_loss / len(test_dataloader)
test_losses.append(avg_test_loss)
accuracy = total_correct / test_data_size
test_accuracies.append(accuracy)
# 更新总进度条描述
epoch_progress.set_postfix({
"训练损失": f"{avg_train_loss:.4f}",
"测试损失": f"{avg_test_loss:.4f}",
"测试准确率": f"{accuracy:.4f}"
})
# 保存模型
torch.save(model.state_dict(), f"./check_point/{model_name}/classify_model_{i+1}.pth")
# 每10个epoch保存一次图表
if (i + 1) % 10 == 0 or i == epoch - 1:
# 创建图表
plt.figure(figsize=(12, 5))
# 损失图表
plt.subplot(1, 2, 1)
plt.plot(range(1, i+2), train_losses, label='Training loss')
plt.plot(range(1, i+2), test_losses, label='Test loss')
plt.xlabel('Epoch')
plt.ylabel('Loss')
plt.title('Training and testing losses')
plt.legend()
plt.grid(True)
# 准确率图表
plt.subplot(1, 2, 2)
plt.plot(range(1, i+2), test_accuracies, label='Test accuracy', color='green')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.title('Test accuracy')
plt.ylim(0, 1.0)
plt.legend()
plt.grid(True)
plt.tight_layout()
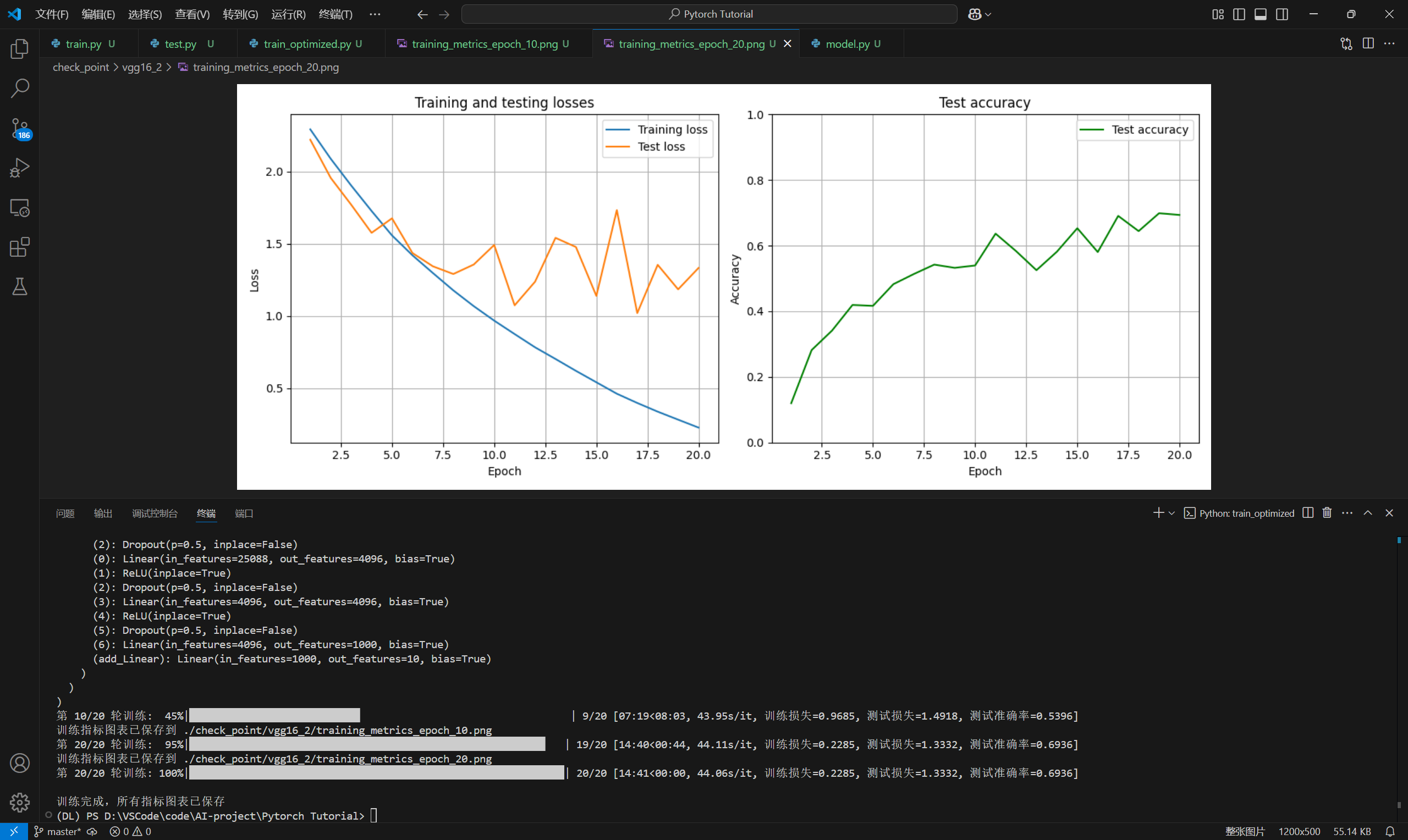
plt.savefig(f'./check_point/{model_name}/training_metrics_epoch_{i+1}.png')
plt.close()
print(f"\n训练指标图表已保存到 ./check_point/{model_name}/training_metrics_epoch_{i+1}.png")
print("\n训练完成,所有指标图表已保存")
效果演示
训练过程
测试过程
 wechat
wechat- alipay

