
AdvDreamer
1.《AdvDreamer Unveils: Are Vision-Language Models Truly Ready for Real-World 3D Variations?》
1.1 概述
Vision Language Models(VLMs)有优秀的泛化能力,然而VLMs在动态的现实场景中的鲁棒性仍未广泛探索。
本文提出了AdvDreamer,可以从图片的单一视角生成物理上可再生的对抗性3D转变换样本(Adv-3DT),实验表明在现实世界中的3D变种可能对模型在不同任务上的表现造成严重的威胁。

本文主要探究目前的VLMs对于处理来自真实世界中3D变种的分布变换是否具有充分的鲁棒性。
提出一个新颖的框架AdvDreamer,从一张自然的图片生成现实世界中的Adv-3DT样本
引入Naturalness Reward Model(NRM),在优化过程中维持样本的自然性,确保分布与现实世界中的图片一致,确保样本是物理上可再生的
- Inverse Semantic Probability objective(ISP)保证Adv-3DT样本在不同的VLM架构和下游任务中的可转移性
- Multimodal 3D Transformation VQA Benchmark(MM3DTBench),其中包含由 AdvDreamer 生成或从物理环境中复现的最具挑战性的 Adv-3DT 样本以及它们的物理上再生产物。
1.2 AdvDreamer框架
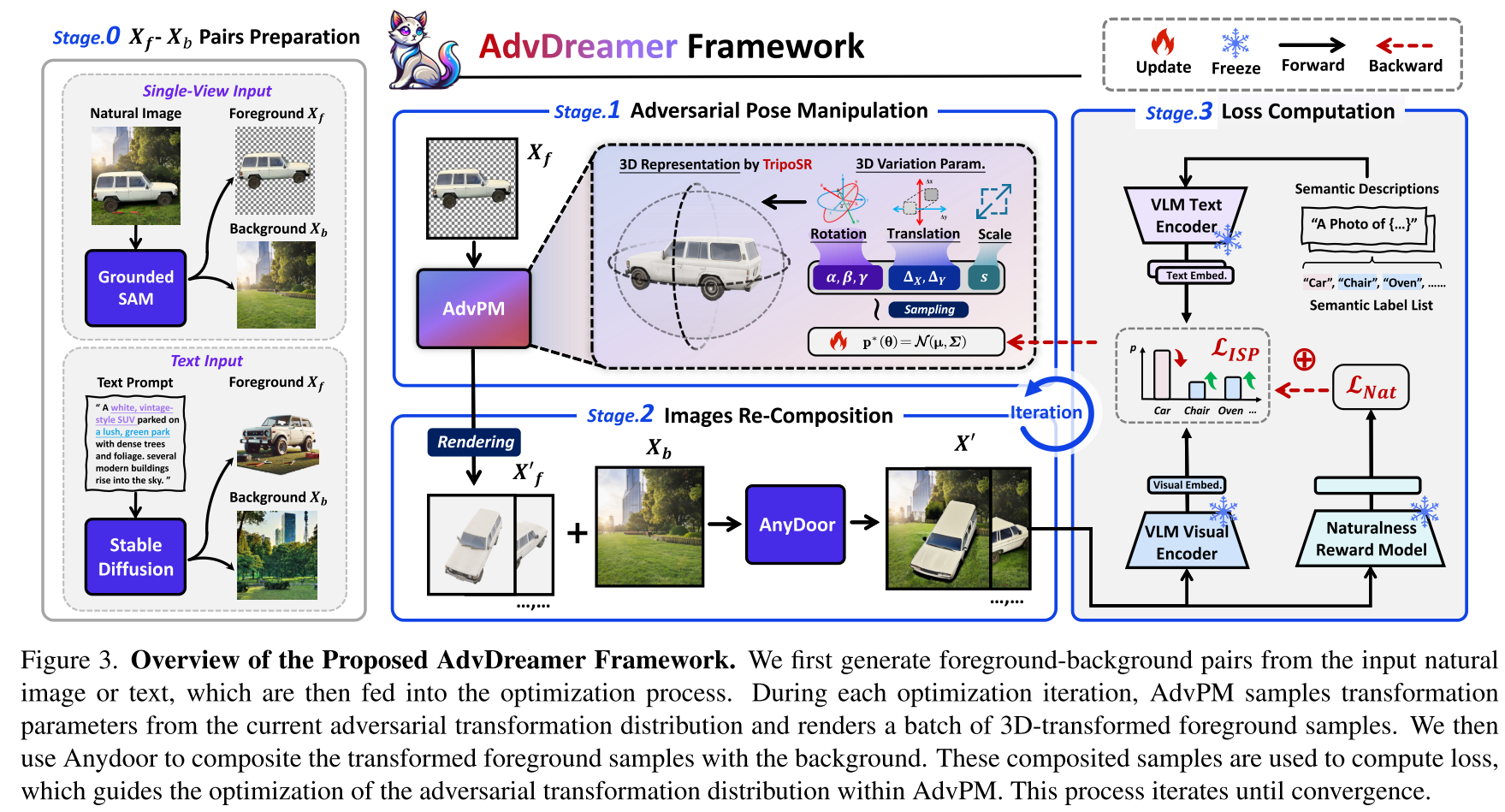
- Step0:前景-背景对的准备阶段(Foreground-Background Pairs Preparation)
将输入的图片X分解成前景-背景对${X_f,X_b}$
采用Grounded-SAM将主要实例从语义上分割为前景$X_f$,然后进行基于扩散的修复以获得完整的背景$X_b$
此外,采用Stable-Diffusion直接生成前景-背景对来增强样本多样性
- Step1:对抗性姿势操纵(Adversarial Pose Manipulation,AdvPM)
采用对抗姿态操纵器 (AdvPM) 将前景 $X_f$ 变换为一批 $X^,_f$,这些 $X^,_f$ 是在从当前 $p(\theta)$ 采样的 $\theta$ 下生成的
AdvPM 利用最先进的Large Reconstruction Model (LRM) ,TripoSR 提供的稳健先验知识,构建基于单视图的 3D 表示并应用采样变换
- Step2:图像的重新合成
通过AnyDoor(一种基于扩散的合成模型)将变换后的前景$X^,_f$与背景合成
- Step3:损失计算和分布优化
对于每个合成的样本 $X^,$,我们进一步计算其损失以指导对抗分布的更新
通过迭代执行第 1-3 阶段,AdvDreamer 收敛到最优分布 $p^(\theta)$,从 $p^(\theta)$中采样并应用生成过程可得到多样化的 Adv-3DT 样本
此外,分布中心对应于最坏情况的 Adv-3DT 样本
感觉这里涉及到很多我未知的领域,比如1)采用Ground-SAM将实例分割为前景,2)采用Stable-Diffusion直接合成前景-背景对,3)大型重建模型(Large Reconstruction Model,LRM)TripoSR 建立基于单一视角的3D表现,4)基于扩散的合成模型AnyDoor
但是我可以理解整个流程的大致意图,首先将自然图片分割成前景和背景对,然后通过平移、旋转和缩放变换前景,再将变换后的前景与背景融合,最后基于损失不断迭代优化得到最优分布,从最优分布中采样并应用于生成过程即可得到多样化的Adv-3DT样本,达到欺骗VLMs的目的
1.3 核心模块
1.3.1 Inverse Semantic Probability Objective
旨在最小化 VLMs 分配给 Adv-3DT 样本的真实语义属性的概率
仅仅基于视觉编码器和文本编码器,它们是现代VLM架构的基础组成部分,这样可以确保AdvDreamer在VLM的架构不可知时也起作用
在视觉-文本对齐空间操作而不是特定模型的层或特定任务的头,使得AdvDreamer具有任务泛化能力

1.3.2 Naturalness Reward Model
尽管生成模型提供了 3D 先验和逼真的图像效果,但直接优化 $L_{IPS}$ 通常会导致不自然的样本,例如形状扭曲和物理上不可信的情况
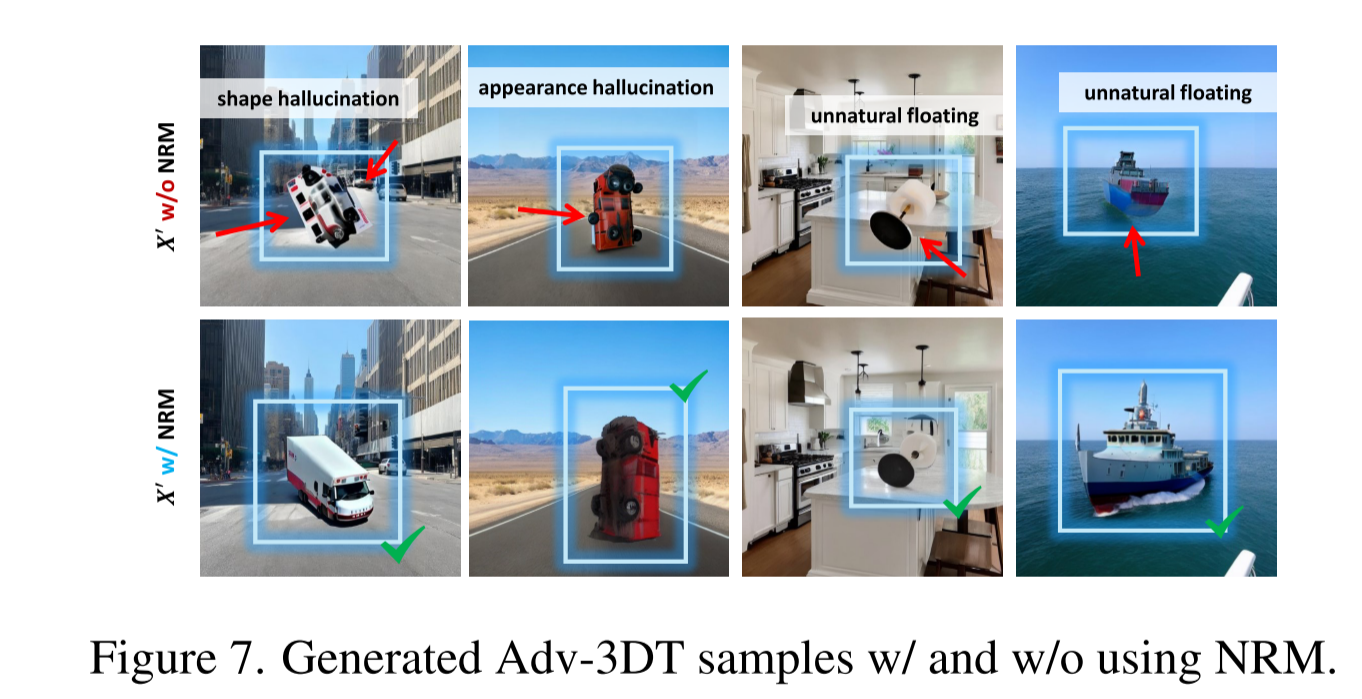
在优化过程中根据样本的自然性不断对 $p(\theta)$ 进行正则化,防止收敛到低质量的“伪最优”区域。
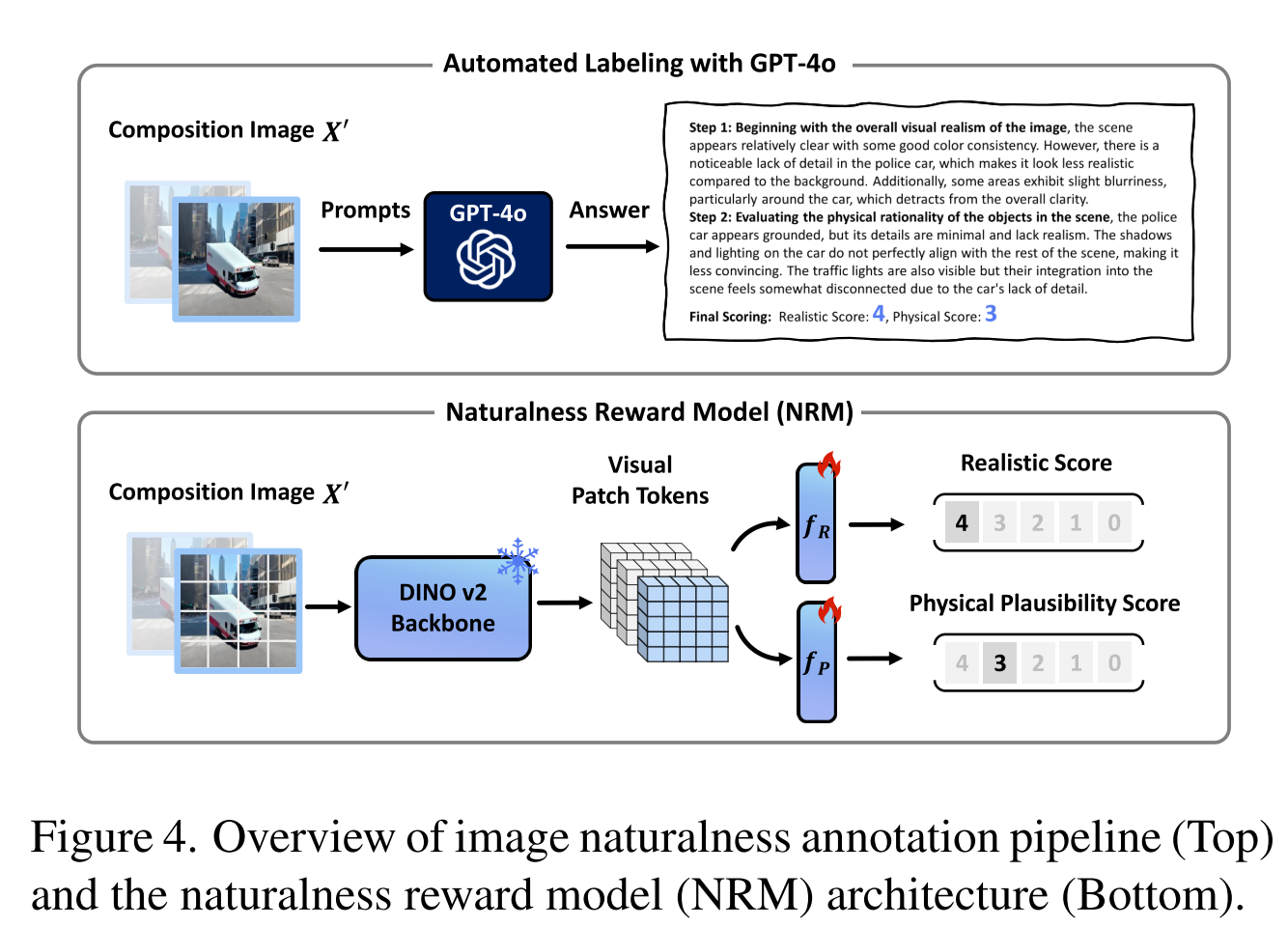
- 利用 GPT-4o 创建了一个大规模训练集,通过自动标注 10 万个精心挑选的样本的自然度
- 标注考虑两个标准:视觉真实度和物理可信度,每个标准均采用 5 分制进行量化
- 使用 DINOv2 作为骨干网络,以提取稳健且丰富的视觉特征,然后使用双流预测头进行真实度和物理可信度评分
1.3.3 Query-Based Black-box Optimization
通常方法是计算损失函数相对于分布参数 $\mu$ 和 $\sum$ 的梯度,并通过梯度上升来更新它们。然而,由于前向过程涉及多个模型组件,这在梯度传播路径中引入了不确定性,使得利用梯度信息进行优化变得具有挑战性
因此,实验者采用了协方差矩阵自适应进化策略 (Covariance Matrix Adaptation Evolution Strategy,CMA-ES) ,这是一种高效的基于查询的黑盒优化器,核心算法如下

1.4 我的想法
本文讨论了视觉语言模型在真实世界3D变化中的鲁棒性问题。实验者全面评估揭示了现有 VLMs 存在严重的鲁棒性缺陷,凸显了在安全关键应用中增强 VLM 的 3D 变化感知和理解能力的迫切需求。
本文的创新在于1)对抗性攻击在计算机视觉中已有广泛研究,但大多数集中在2D扰动上,3D对抗攻击的研究相对较少,尤其是结合生成模型的方法。2)逆语义概率目标(ISP),通过攻击VLMs的视觉-文本对齐空间,而非特定的任务层,确保对抗性样本的跨模型和跨任务的泛化能力。3)自然性奖励模型(NRM),使对抗性样本在视觉上自然且物理上合理,避免模型向“伪最优”区域收敛。4)MM3DTBench ,建立标准化评估工具,为后续研究提供了统一的评估工具。
我对文中较多的方法和概念理解比较模糊,比如对抗性样本的生成方式TripoSR和Stable Diffusion,以及优化算法中CMA-ES优化策略,只对核心流程有大概把握,后续若需要运用再深入了解。
本文可拓展的地方有1)文章仅探究平移、旋转、缩放变换对VLMs的影响,未来可探索非刚性变换对VLMs的影响 2)是否可以通过对抗性训练来防御AdvDreamer的攻击
2.相关工作调研
2.1 任务要求
这周把这个文章学习下,围绕这篇文章调研一下什么是世界模型,有哪些种类
Dreamer是世界模型的一种,简单来讲就是一个大预测模型,可以基于你当前的内容预测下一秒中发生的事情,本质上是一种预测和生成模型,抽象上理解就是全知的, 上帝视角的模型,所以叫世界模型
2.2 工作进展
2.2.1 3D对抗攻击
AdvDreamer中没有看到对世界模型的定义和解释,文章重点在于视觉语言模型对3D对抗性变换样本的鲁棒性,于是我查找了与该文章相关的3D对抗攻击的工作
| 标题 | 会议/期刊 | 备注 |
|---|---|---|
| 《ViewFool: Evaluating the Robustness of Visual Recognition to Adversarial Viewpoints》 | NeurIPS 2022 | 这篇文章和AdvDreamer极其相似,都是探究现有的视觉模型对3D视角变换的鲁棒性问题。该文章提出ViewFool方法【AdvDreamer方法】,利用神经辐射场(NeRF)【前景-背景对】编码真实的物体,生成对抗性视角【基于扩散模型和LRM】,引入熵正则化缩小NeRF表示与真实物体之间的差距【ISP】【NRM自然反馈模型】,构建ImageNet-V数据集用于评估模型再视角变化下的鲁棒性【MM3DTBench】。结果表明对抗性视角具有跨模型迁移能力。 |
| 《Strike (with) a Pose: Neural Networks Are Easily Fooled by Strange Poses of Familiar Objects》 | CVPR 2019 | 深度神经网络(DNNs)在固定测试集上表现优异,但在面对现实中的分布外(OoD)输入时,尤其是自然非对抗性的3D姿态变化时泛化能力不足。这篇文章提出了一个利用3D渲染器和3D模型来发现DNN故障的框架,并通过实验展示了DNN对姿态变化的脆弱性,以及对抗姿态在不同模型和数据集间的迁移性。 |
2.2.2 世界模型
| 信息来源 | 备注 |
|---|---|
| World Models | NIPS 2018 本文探索构建生成式神经网络模型,用于模拟强化学习环境,提升智能体训练效率与泛化能力【摘要】 |
| https://www.nvidia.cn/glossary/world-models/ | Nvidia官网给出对世界模型的定义,现实世界中世界基础模型的应用,世界模型的优势,以及构建世界模型的方法 |
| https://worldmodels.github.io/ | World Models可交互版的形式 |
定义
世界模型是理解现实世界动态 (包括其物理和空间属性) 的生成式 AI 模型。它们使用文本、图像、视频和运动等输入数据来生成视频。通过学习,它们能够理解现实世界环境的物理特性,从而对运动、应力以及感官数据中的空间关系等动态进行表示和预测。
世界模型本质上是一种环境动态的抽象表征系统,其核心功能在于通过有限观测数据构建可推理的潜在空间。通过整合文本、图像、视频等多模态输入数据,建立对物理空间属性和社会交互规律的深度学习
我的理解,世界模型从多模态输入中理解现实世界环境的物理特性,从而做出相关的表示和预测。世界模型是理解环境动态与支持智能决策的AI模型,能够模拟现实世界物理规律与社会交互的认知架构。
分类
deepseek根据功能和技术,将世界模型分为以下两类:
- 基于内部表征的世界模型
构建对当前世界状态的抽象理解,形成环境动态的隐式表征。
通常结合变分自编码器(VAE)、循环神经网络(RNN)等架构,将高维观测数据压缩为低维潜变量,用于后续决策。
- 基于未来预测的世界模型
预测环境未来状态的变化,指导实时决策。
侧重于生成未来场景的逼真模拟,如OpenAI的Sora模型可生成遵循物理规律的视频,特斯拉的通用世界模型能预测车辆轨迹。
gpt4o根据建模目标、结构特征、训练方法将世界模型分类如下
建模目标视角:生成式 vs 判别式
生成式世界模型旨在学习环境的完整动力学分布,即预测下一个观测(或状态)的概率分布,通过重构或生成未来帧来模拟环境演
判别式世界模型只学习与规划决策最相关的输出,而不生成完整观测
结构特征:显式模型 vs 隐式模型。
显式世界模型指模型结构中明确存在环境预测组件,能生成完整观测或状态序列
隐式世界模型则没有独立的环境模拟器,而是将环境信息隐含在模型参数或智能体状态中
显式建模先明确构建环境动态模型,再用其进行规划。
隐式模型更多见于一些基于记忆的策略网络,它们通过内在记忆或网络结构捕获环境规律,但不显式输出状态预测。
训练方式:监督学习 vs 无监督学习 vs 强化学习结合
在实际应用中,世界模型常通过无监督或自监督方式训练环境动态,部分工作也会将世界模型训练与强化学习目标结合
Dreamer等方法则在生成模型学习的基础上,通过策略或价值模型在潜在空间中优化行为。
监督学习少见于环境建模领域,除非能获得真实的状态转移标签。总体来看,现代世界模型多采用无监督学习或自监督学习来学习环境表示,并结合强化学习来训练决策模块,以实现高效智能体训练。
我的想法
感觉调研的过程比读论文的过程更加困难,上面的调研缺乏对世界模型架构的认知,没有涉及世界模型的组成、如何训练世界模型、世界模型在现实世界的应用等更广泛的问题,且上述调研工作依赖于perplexity、gpt4o、deepseek等模型提供方向,深度和广度都有所欠缺。
对于一个全新领域的调研工作,应该从何开始着手,如何深入挖掘等问题仍待解决。
 wechat
wechat- alipay

