
知识图谱
工作总结
1.GraphRAG本地部署
若有OpenAI密钥可直接按照graphrag官网的步骤进行graphrag的本地部署和使用
一般用户没有OpenAI密钥可以考虑使用其他可获得的密钥或者用Ollama+llama进行本地大模型部署,需要注意的是本地大模型部署对电脑配置要求比较高,建议还是使用api接口
以下讲解GraphRAG在不用OpenAI密钥的情况下的部署
1.1基础配置
创建项目graphrag(也可以取其他名称,这里方便后续说明)及相应虚拟环境,注意python版本为3.10-3.12
安装graphrag库:1
pip install graphrag
创建目录test(也可以是其他名称,这里确定为test方便后续说明)
在test目录下创建目录input,在input目录下存放要进行索引构建的文本文件
完成后当前文件树结构为:
graphrag
└─test
└─input
└─book.txt
初始化test目录1
python -m graphrag.index --init --root ./test
初始化时会生成其他文件夹和文件,完成后当前文件树结构为:
graphrag
└─test
│ .env
│ settings.yaml
│
├─input
│ book.txt
│
├─output
│ └─20240914-170402
│ └─reports
│ indexing-engine.log
│
└─prompts
claim_extraction.txt
community_report.txt
entity_extraction.txt
summarize_descriptions.txt
至此,基本配置结束
1.2使用Ollama+llama进行本地部署
可以参考b站视频
笔者也是通过该视频完成了Ollama+llama本地部署graphrag
Ollama官网:https://ollama.com/
Ollama相关命令1
ollama pull llama3.1 # 拉取模型
1
ollama run llama3.1 # 运行模型
1
ollama serve # 开启服务
相关文件
该视频已给出文件百度网盘下载地址,也可以直接复制粘贴此处已下好的文件内容
settings.yaml:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147encoding_model: cl100k_base
skip_workflows: []
llm:
api_key: sk-djdjsjdj
type: openai_chat # or azure_openai_chat
#model: glm4:9b-chat-q6_K
model: llama3.1
model_supports_json: true # recommended if this is available for your model.
# max_tokens: 4000
# request_timeout: 180.0
api_base: http://localhost:11434/v1
# api_version: 2024-02-15-preview
# organization: <organization_id>
# deployment_name: <azure_model_deployment_name>
# tokens_per_minute: 150_000 # set a leaky bucket throttle
# requests_per_minute: 10_000 # set a leaky bucket throttle
# max_retries: 10
# max_retry_wait: 10.0
# sleep_on_rate_limit_recommendation: true # whether to sleep when azure suggests wait-times
# concurrent_requests: 25 # the number of parallel inflight requests that may be made
parallelization:
stagger: 0.3
# num_threads: 50 # the number of threads to use for parallel processing
async_mode: threaded # or asyncio
embeddings:
## parallelization: override the global parallelization settings for embeddings
async_mode: threaded # or asyncio
llm:
api_key: sk-djdjsjdj
type: openai_embedding # or azure_openai_embedding
model: nomic-embed-text
#model: nomic_embed_text
api_base: http://localhost:11434/api
#api_base: http://localhost:11434/v1
# api_version: 2024-02-15-preview
# organization: <organization_id>
# deployment_name: <azure_model_deployment_name>
# tokens_per_minute: 150_000 # set a leaky bucket throttle
# requests_per_minute: 10_000 # set a leaky bucket throttle
# max_retries: 10
# max_retry_wait: 10.0
# sleep_on_rate_limit_recommendation: true # whether to sleep when azure suggests wait-times
# concurrent_requests: 25 # the number of parallel inflight requests that may be made
# batch_size: 16 # the number of documents to send in a single request
# batch_max_tokens: 8191 # the maximum number of tokens to send in a single request
# target: required # or optional
chunks:
size: 300
overlap: 100
group_by_columns: [id] # by default, we don't allow chunks to cross documents
input:
type: file # or blob
file_type: text # or csv
base_dir: "input"
file_encoding: utf-8
file_pattern: ".*\\.txt$"
cache:
type: file # or blob
base_dir: "cache"
# connection_string: <azure_blob_storage_connection_string>
# container_name: <azure_blob_storage_container_name>
storage:
type: file # or blob
base_dir: "output/${timestamp}/artifacts"
# connection_string: <azure_blob_storage_connection_string>
# container_name: <azure_blob_storage_container_name>
reporting:
type: file # or console, blob
base_dir: "output/${timestamp}/reports"
# connection_string: <azure_blob_storage_connection_string>
# container_name: <azure_blob_storage_container_name>
entity_extraction:
## llm: override the global llm settings for this task
## parallelization: override the global parallelization settings for this task
## async_mode: override the global async_mode settings for this task
prompt: "prompts/entity_extraction.txt"
entity_types: [organization,person,geo,event]
max_gleanings: 0
summarize_descriptions:
## llm: override the global llm settings for this task
## parallelization: override the global parallelization settings for this task
## async_mode: override the global async_mode settings for this task
prompt: "prompts/summarize_descriptions.txt"
max_length: 500
claim_extraction:
## llm: override the global llm settings for this task
## parallelization: override the global parallelization settings for this task
## async_mode: override the global async_mode settings for this task
# enabled: true
prompt: "prompts/claim_extraction.txt"
description: "Any claims or facts that could be relevant to information discovery."
max_gleanings: 0
community_report:
## llm: override the global llm settings for this task
## parallelization: override the global parallelization settings for this task
## async_mode: override the global async_mode settings for this task
prompt: "prompts/community_report.txt"
max_length: 2000
max_input_length: 8000
cluster_graph:
max_cluster_size: 10
embed_graph:
enabled: false # if true, will generate node2vec embeddings for nodes
# num_walks: 10
# walk_length: 40
# window_size: 2
# iterations: 3
# random_seed: 597832
umap:
enabled: false # if true, will generate UMAP embeddings for nodes
snapshots:
graphml: false
raw_entities: false
top_level_nodes: false
local_search:
# text_unit_prop: 0.5
# community_prop: 0.1
# conversation_history_max_turns: 5
# top_k_mapped_entities: 10
# top_k_relationships: 10
# max_tokens: 12000
global_search:
# max_tokens: 12000
# data_max_tokens: 12000
# map_max_tokens: 1000
# reduce_max_tokens: 2000
# concurrency: 32
community_report.txt:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145You are an AI assistant that helps a human analyst to perform general information discovery. Information discovery is the process of identifying and assessing relevant information associated with certain entities (e.g., organizations and individuals) within a network.
# Goal
Write a comprehensive report of a community, given a list of entities that belong to the community as well as their relationships and optional associated claims. The report will be used to inform decision-makers about information associated with the community and their potential impact. The content of this report includes an overview of the community's key entities, their legal compliance, technical capabilities, reputation, and noteworthy claims.
# Report Structure
The report should include the following sections:
- TITLE: community's name that represents its key entities - title should be short but specific. When possible, include representative named entities in the title.
- SUMMARY: An executive summary of the community's overall structure, how its entities are related to each other, and significant information associated with its entities.
- IMPACT SEVERITY RATING: a float score between 0-10 that represents the severity of IMPACT posed by entities within the community. IMPACT is the scored importance of a community.
- RATING EXPLANATION: Give a single sentence explanation of the IMPACT severity rating.
- DETAILED FINDINGS: A list of 5-10 key insights about the community. Each insight should have a short summary followed by multiple paragraphs of explanatory text grounded according to the grounding rules below. Be comprehensive.
Return output as a well-formed JSON-formatted string with the following format:
{
"title": <report_title>,
"summary": <executive_summary>,
"rating": <impact_severity_rating>,
"rating_explanation": <rating_explanation>,
"findings": [
{
"summary":<insight_1_summary>,
"explanation": <insight_1_explanation>
},
{
"summary":<insight_2_summary>,
"explanation": <insight_2_explanation>
}
]
}
# Grounding Rules
Points supported by data should list their data references as follows:
"This is an example sentence supported by multiple data references [Data: <dataset name> (record ids); <dataset name> (record ids)]."
Do not list more than 5 record ids in a single reference. Instead, list the top 5 most relevant record ids and add "+more" to indicate that there are more.
For example:
"Person X is the owner of Company Y and subject to many allegations of wrongdoing [Data: Reports (1), Entities (5, 7); Relationships (23); Claims (7, 2, 34, 64, 46, +more)]."
where 1, 5, 7, 23, 2, 34, 46, and 64 represent the id (not the index) of the relevant data record.
Do not include information where the supporting evidence for it is not provided.
# Example Input
-----------
Text:
Entities
id,entity,description
5,VERDANT OASIS PLAZA,Verdant Oasis Plaza is the location of the Unity March
6,HARMONY ASSEMBLY,Harmony Assembly is an organization that is holding a march at Verdant Oasis Plaza
Relationships
id,source,target,description
37,VERDANT OASIS PLAZA,UNITY MARCH,Verdant Oasis Plaza is the location of the Unity March
38,VERDANT OASIS PLAZA,HARMONY ASSEMBLY,Harmony Assembly is holding a march at Verdant Oasis Plaza
39,VERDANT OASIS PLAZA,UNITY MARCH,The Unity March is taking place at Verdant Oasis Plaza
40,VERDANT OASIS PLAZA,TRIBUNE SPOTLIGHT,Tribune Spotlight is reporting on the Unity march taking place at Verdant Oasis Plaza
41,VERDANT OASIS PLAZA,BAILEY ASADI,Bailey Asadi is speaking at Verdant Oasis Plaza about the march
43,HARMONY ASSEMBLY,UNITY MARCH,Harmony Assembly is organizing the Unity March
Output:
{
"title": "Verdant Oasis Plaza and Unity March",
"summary": "The community revolves around the Verdant Oasis Plaza, which is the location of the Unity March. The plaza has relationships with the Harmony Assembly, Unity March, and Tribune Spotlight, all of which are associated with the march event.",
"rating": 5.0,
"rating_explanation": "The impact severity rating is moderate due to the potential for unrest or conflict during the Unity March.",
"findings": [
{
"summary": "Verdant Oasis Plaza as the central location",
"explanation": "Verdant Oasis Plaza is the central entity in this community, serving as the location for the Unity March. This plaza is the common link between all other entities, suggesting its significance in the community. The plaza's association with the march could potentially lead to issues such as public disorder or conflict, depending on the nature of the march and the reactions it provokes. [Data: Entities (5), Relationships (37, 38, 39, 40, 41,+more)]"
},
{
"summary": "Harmony Assembly's role in the community",
"explanation": "Harmony Assembly is another key entity in this community, being the organizer of the march at Verdant Oasis Plaza. The nature of Harmony Assembly and its march could be a potential source of threat, depending on their objectives and the reactions they provoke. The relationship between Harmony Assembly and the plaza is crucial in understanding the dynamics of this community. [Data: Entities(6), Relationships (38, 43)]"
},
{
"summary": "Unity March as a significant event",
"explanation": "The Unity March is a significant event taking place at Verdant Oasis Plaza. This event is a key factor in the community's dynamics and could be a potential source of threat, depending on the nature of the march and the reactions it provokes. The relationship between the march and the plaza is crucial in understanding the dynamics of this community. [Data: Relationships (39)]"
},
{
"summary": "Role of Tribune Spotlight",
"explanation": "Tribune Spotlight is reporting on the Unity March taking place in Verdant Oasis Plaza. This suggests that the event has attracted media attention, which could amplify its impact on the community. The role of Tribune Spotlight could be significant in shaping public perception of the event and the entities involved. [Data: Relationships (40)]"
}
]
}
# Real Data
Use the following text for your answer. Do not make anything up in your answer.
Text:
{input_text}
The report should include the following sections:
- TITLE: community's name that represents its key entities - title should be short but specific. When possible, include representative named entities in the title.
- SUMMARY: An executive summary of the community's overall structure, how its entities are related to each other, and significant information associated with its entities.
- IMPACT SEVERITY RATING: a float score between 0-10 that represents the severity of IMPACT posed by entities within the community. IMPACT is the scored importance of a community.
- RATING EXPLANATION: Give a single sentence explanation of the IMPACT severity rating.
- DETAILED FINDINGS: A list of 5-10 key insights about the community. Each insight should have a short summary followed by multiple paragraphs of explanatory text grounded according to the grounding rules below. Be comprehensive.
Return output as a well-formed JSON-formatted string with the following format:
{
"title": <report_title>,
"summary": <executive_summary>,
"rating": <impact_severity_rating>,
"rating_explanation": <rating_explanation>,
"findings": [
{
"summary":<insight_1_summary>,
"explanation": <insight_1_explanation>
},
{
"summary":<insight_2_summary>,
"explanation": <insight_2_explanation>
}
]
}
# Grounding Rules
Points supported by data should list their data references as follows:
"This is an example sentence supported by multiple data references [Data: <dataset name> (record ids); <dataset name> (record ids)]."
Do not list more than 5 record ids in a single reference. Instead, list the top 5 most relevant record ids and add "+more" to indicate that there are more.
For example:
"Person X is the owner of Company Y and subject to many allegations of wrongdoing [Data: Reports (1), Entities (5, 7); Relationships (23); Claims (7, 2, 34, 64, 46, +more)]."
where 1, 5, 7, 23, 2, 34, 46, and 64 represent the id (not the index) of the relevant data record.
Do not include information where the supporting evidence for it is not provided.
Output:
embedding.py:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159# Copyright (c) 2024 Microsoft Corporation.
# Licensed under the MIT License
"""OpenAI Embedding model implementation."""
import asyncio
from collections.abc import Callable
from typing import Any
import ollama
import numpy as np
import tiktoken
from tenacity import (
AsyncRetrying,
RetryError,
Retrying,
retry_if_exception_type,
stop_after_attempt,
wait_exponential_jitter,
)
from graphrag.query.llm.base import BaseTextEmbedding
from graphrag.query.llm.oai.base import OpenAILLMImpl
from graphrag.query.llm.oai.typing import (
OPENAI_RETRY_ERROR_TYPES,
OpenaiApiType,
)
from graphrag.query.llm.text_utils import chunk_text
from graphrag.query.progress import StatusReporter
class OpenAIEmbedding(BaseTextEmbedding, OpenAILLMImpl):
"""Wrapper for OpenAI Embedding models."""
def __init__(
self,
api_key: str | None = None,
azure_ad_token_provider: Callable | None = None,
model: str = "text-embedding-3-small",
deployment_name: str | None = None,
api_base: str | None = None,
api_version: str | None = None,
api_type: OpenaiApiType = OpenaiApiType.OpenAI,
organization: str | None = None,
encoding_name: str = "cl100k_base",
max_tokens: int = 8191,
max_retries: int = 10,
request_timeout: float = 180.0,
retry_error_types: tuple[type[BaseException]] = OPENAI_RETRY_ERROR_TYPES, # type: ignore
reporter: StatusReporter | None = None,
):
OpenAILLMImpl.__init__(
self=self,
api_key=api_key,
azure_ad_token_provider=azure_ad_token_provider,
deployment_name=deployment_name,
api_base=api_base,
api_version=api_version,
api_type=api_type, # type: ignore
organization=organization,
max_retries=max_retries,
request_timeout=request_timeout,
reporter=reporter,
)
self.model = model
self.encoding_name = encoding_name
self.max_tokens = max_tokens
self.token_encoder = tiktoken.get_encoding(self.encoding_name)
self.retry_error_types = retry_error_types
self.embedding_dim = 384 # Nomic-embed-text model dimension
self.ollama_client = ollama.Client()
def embed(self, text: str, **kwargs: Any) -> list[float]:
"""Embed text using Ollama's nomic-embed-text model."""
try:
embedding = self.ollama_client.embeddings(model="nomic-embed-text", prompt=text)
return embedding["embedding"]
except Exception as e:
self._reporter.error(
message="Error embedding text",
details={self.__class__.__name__: str(e)},
)
return np.zeros(self.embedding_dim).tolist()
async def aembed(self, text: str, **kwargs: Any) -> list[float]:
"""Embed text using Ollama's nomic-embed-text model asynchronously."""
try:
embedding = await self.ollama_client.embeddings(model="nomic-embed-text", prompt=text)
return embedding["embedding"]
except Exception as e:
self._reporter.error(
message="Error embedding text asynchronously",
details={self.__class__.__name__: str(e)},
)
return np.zeros(self.embedding_dim).tolist()
def _embed_with_retry(
self, text: str | tuple, **kwargs: Any #str | tuple
) -> tuple[list[float], int]:
try:
retryer = Retrying(
stop=stop_after_attempt(self.max_retries),
wait=wait_exponential_jitter(max=10),
reraise=True,
retry=retry_if_exception_type(self.retry_error_types),
)
for attempt in retryer:
with attempt:
embedding = (
self.sync_client.embeddings.create( # type: ignore
input=text,
model=self.model,
**kwargs, # type: ignore
)
.data[0]
.embedding
or []
)
return (embedding["embedding"], len(text))
except RetryError as e:
self._reporter.error(
message="Error at embed_with_retry()",
details={self.__class__.__name__: str(e)},
)
return ([], 0)
else:
# TODO: why not just throw in this case?
return ([], 0)
async def _aembed_with_retry(
self, text: str | tuple, **kwargs: Any
) -> tuple[list[float], int]:
try:
retryer = AsyncRetrying(
stop=stop_after_attempt(self.max_retries),
wait=wait_exponential_jitter(max=10),
reraise=True,
retry=retry_if_exception_type(self.retry_error_types),
)
async for attempt in retryer:
with attempt:
embedding = (
await self.async_client.embeddings.create( # type: ignore
input=text,
model=self.model,
**kwargs, # type: ignore
)
).data[0].embedding or []
return (embedding, len(text))
except RetryError as e:
self._reporter.error(
message="Error at embed_with_retry()",
details={self.__class__.__name__: str(e)},
)
return ([], 0)
else:
# TODO: why not just throw in this case?
return ([], 0)
openai_embeddings_llm.py:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40# Copyright (c) 2024 Microsoft Corporation.
# Licensed under the MIT License
"""The EmbeddingsLLM class."""
from typing_extensions import Unpack
from graphrag.llm.base import BaseLLM
from graphrag.llm.types import (
EmbeddingInput,
EmbeddingOutput,
LLMInput,
)
from .openai_configuration import OpenAIConfiguration
from .types import OpenAIClientTypes
import ollama
class OpenAIEmbeddingsLLM(BaseLLM[EmbeddingInput, EmbeddingOutput]):
"""A text-embedding generator LLM."""
_client: OpenAIClientTypes
_configuration: OpenAIConfiguration
def __init__(self, client: OpenAIClientTypes, configuration: OpenAIConfiguration):
self.client = client
self.configuration = configuration
async def _execute_llm(
self, input: EmbeddingInput, **kwargs: Unpack[LLMInput]
) -> EmbeddingOutput | None:
args = {
"model": self.configuration.model,
**(kwargs.get("model_parameters") or {}),
}
embedding_list = []
for inp in input:
embedding = ollama.embeddings(model="nomic-embed-text", prompt=inp)
embedding_list.append(embedding["embedding"])
return embedding_list
将相关文件替换后再打开Ollama服务
构建索引:1
python -m graphrag.index --root ./test
这一步比较吃电脑配置,也是最耗时间的一步b站视频演示时用4090的显卡用时20分钟左右,笔者4050的显卡对同样的内容构建索引用时5个小时多
构建完成后会生成新的文件,文件树如下:
1 | <summary>文件树信息</summary> |
查询指令
1 | python -m graphrag.query --root ./test --method global "你要问的问题" |
—method可以有global和local两种方式
目前好像对中文文本的支持不是很好,在进行中文文本的索引构建时总报错。
1.3使用deepseek大模型进行本地部署
使用国内大模型api接口
官网:https://agicto.com/
只需要更改初始化后产生的.env和settings.yaml文件
获取api密钥后将.env和settings.yaml文件更改成如下内容:
.env文件:1
GRAPHRAG_API_KEY=你的密钥
setting.yaml文件1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154encoding_model: cl100k_base
skip_workflows: []
llm:
api_key: ${GRAPHRAG_API_KEY}
type: openai_chat # or azure_openai_chat
model: deepseek-chat
model_supports_json: false # recommended if this is available for your model.
# max_tokens: 4000
# request_timeout: 180.0
api_base: https://api.agicto.cn/v1
# api_version: 2024-02-15-preview
# organization: <organization_id>
# deployment_name: <azure_model_deployment_name>
# tokens_per_minute: 150_000 # set a leaky bucket throttle
# requests_per_minute: 10_000 # set a leaky bucket throttle
# max_retries: 10
# max_retry_wait: 10.0
# sleep_on_rate_limit_recommendation: true # whether to sleep when azure suggests wait-times
# concurrent_requests: 25 # the number of parallel inflight requests that may be made
# temperature: 0 # temperature for sampling
# top_p: 1 # top-p sampling
# n: 1 # Number of completions to generate
parallelization:
stagger: 0.3
# num_threads: 50 # the number of threads to use for parallel processing
async_mode: threaded # or asyncio
embeddings:
## parallelization: override the global parallelization settings for embeddings
async_mode: threaded # or asyncio
llm:
api_key: ${GRAPHRAG_API_KEY}
type: openai_embedding # or azure_openai_embedding
model: text-embedding-3-small
api_base: https://api.agicto.cn/v1
# api_version: 2024-02-15-preview
# organization: <organization_id>
# deployment_name: <azure_model_deployment_name>
# tokens_per_minute: 150_000 # set a leaky bucket throttle
# requests_per_minute: 10_000 # set a leaky bucket throttle
# max_retries: 10
# max_retry_wait: 10.0
# sleep_on_rate_limit_recommendation: true # whether to sleep when azure suggests wait-times
# concurrent_requests: 25 # the number of parallel inflight requests that may be made
# batch_size: 16 # the number of documents to send in a single request
# batch_max_tokens: 8191 # the maximum number of tokens to send in a single request
# target: required # or optional
chunks:
size: 300
overlap: 100
group_by_columns: [id] # by default, we don't allow chunks to cross documents
input:
type: file # or blob
file_type: text # or csv
base_dir: "input"
file_encoding: utf-8
file_pattern: ".*\\.txt$"
cache:
type: file # or blob
base_dir: "cache"
# connection_string: <azure_blob_storage_connection_string>
# container_name: <azure_blob_storage_container_name>
storage:
type: file # or blob
base_dir: "output/${timestamp}/artifacts"
# connection_string: <azure_blob_storage_connection_string>
# container_name: <azure_blob_storage_container_name>
reporting:
type: file # or console, blob
base_dir: "output/${timestamp}/reports"
# connection_string: <azure_blob_storage_connection_string>
# container_name: <azure_blob_storage_container_name>
entity_extraction:
## llm: override the global llm settings for this task
## parallelization: override the global parallelization settings for this task
## async_mode: override the global async_mode settings for this task
prompt: "prompts/entity_extraction.txt"
entity_types: [organization,person,geo,event]
max_gleanings: 0
summarize_descriptions:
## llm: override the global llm settings for this task
## parallelization: override the global parallelization settings for this task
## async_mode: override the global async_mode settings for this task
prompt: "prompts/summarize_descriptions.txt"
max_length: 500
claim_extraction:
## llm: override the global llm settings for this task
## parallelization: override the global parallelization settings for this task
## async_mode: override the global async_mode settings for this task
# enabled: true
prompt: "prompts/claim_extraction.txt"
description: "Any claims or facts that could be relevant to information discovery."
max_gleanings: 0
community_reports:
## llm: override the global llm settings for this task
## parallelization: override the global parallelization settings for this task
## async_mode: override the global async_mode settings for this task
prompt: "prompts/community_report.txt"
max_length: 2000
max_input_length: 8000
cluster_graph:
max_cluster_size: 10
embed_graph:
enabled: false # if true, will generate node2vec embeddings for nodes
# num_walks: 10
# walk_length: 40
# window_size: 2
# iterations: 3
# random_seed: 597832
umap:
enabled: false # if true, will generate UMAP embeddings for nodes
snapshots:
graphml: false
raw_entities: false
top_level_nodes: false
local_search:
# text_unit_prop: 0.5
# community_prop: 0.1
# conversation_history_max_turns: 5
# top_k_mapped_entities: 10
# top_k_relationships: 10
# llm_temperature: 0 # temperature for sampling
# llm_top_p: 1 # top-p sampling
# llm_n: 1 # Number of completions to generate
# max_tokens: 12000
global_search:
# llm_temperature: 0 # temperature for sampling
# llm_top_p: 1 # top-p sampling
# llm_n: 1 # Number of completions to generate
# max_tokens: 12000
# data_max_tokens: 12000
# map_max_tokens: 1000
# reduce_max_tokens: 2000
# concurrency: 32
然后继续构建索引:1
python -m graphrag.index --root ./test
采用api接口后,这一步骤时间将缩短至10分钟以内
1.4 对GraphRAG的工作流程简单分析
GraphRAG工作流程输出结果: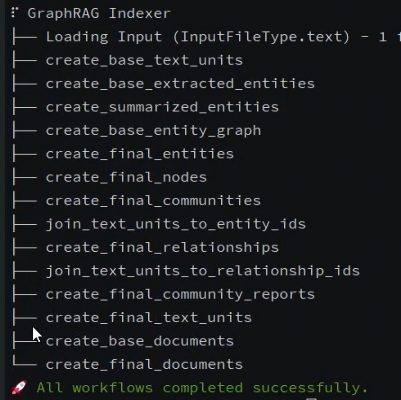
大致工作原理:
构建索引阶段: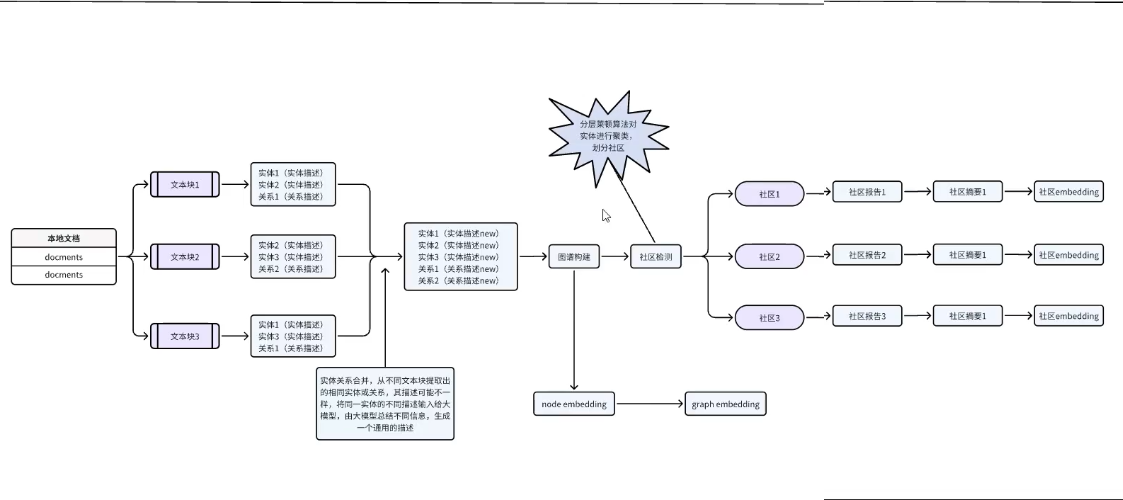
问答阶段: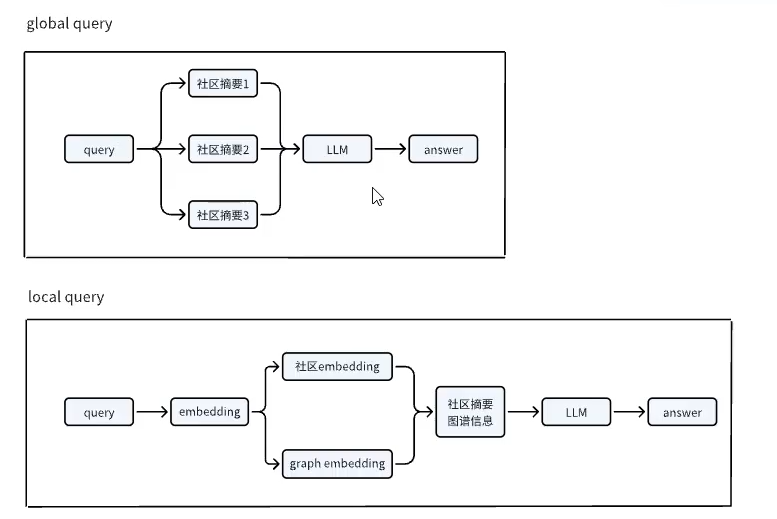
简述:
GraphRAG会对给定的文本文件进行分块处理,每块文段进行命名实体识别,抽取其中的相互关系,再将实体进行分类,形成社区,然后形成社区报告,完成索引的构建。
其中大部分工作是由给定的api接口完成的。在graphrag/test/prompts目录下的文本文件就展示了graphrag向大模型输入的一些工作指令,将具体要完成的工作写在了文本文件里。
在进行问答时有两种不同的模式,global和local,两者所适用的问题类型有所不同。
global模式适合回答全局性的问题,在对各个社区进行总结后得到结果,消耗的资源比较大;
local模式适合回答局域性的问题,消耗资源小。
2. Neo4j可视化知识图谱
2.1 Neo4j部署
neo4j下载地址:https://neo4j.com/deployment-center/#enterprise
进入页面:
往下翻到: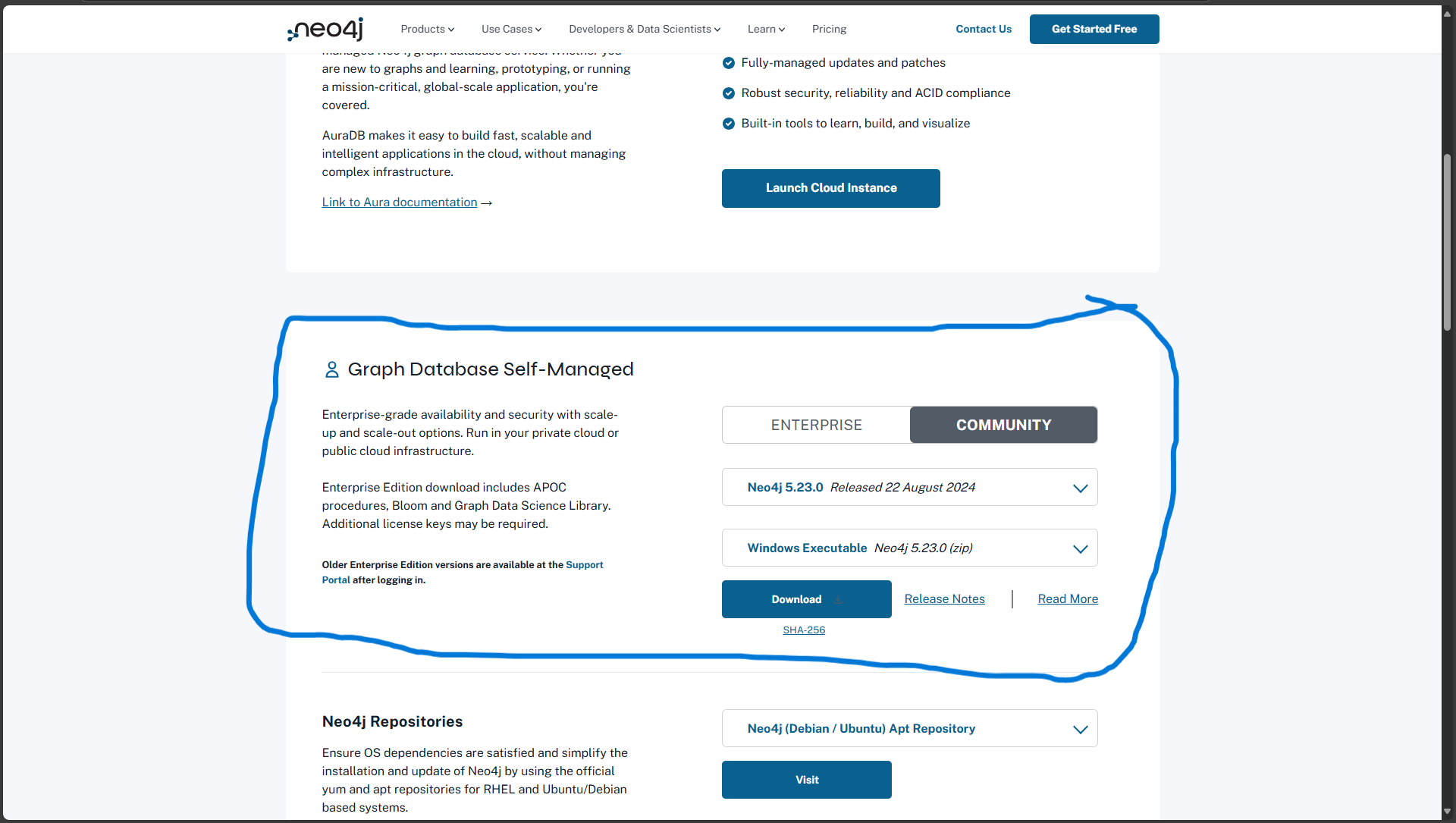
注意选择不收费的COMMUNITY版本和Windows系统版本
点击Download后会下载压缩包neo4j-community-5.23.0-windows.zip
解压后得到文件夹neo4j-community-5.23.0-windows.zip
可以选择将其中的bin目录设置为环境变量,方便后续命令行输入
配置好环境变量后运行以下命令开启neo4j服务:1
neo4j.bat console
默认打开7474端口,在浏览器中搜索 http://localhost:7474 即可访问UI界面
初始用户名和密码均为 neo4j
2.2 将GraphRAG进行可视化操作
- 经过索引构建后test/output/时间戳/artifacts目录下会生成一系列.parquet文件,首先将这些文件转换成.csv文件
转换代码:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29import os
import pandas as pd
import csv
parquet_dir = "./output_csv/test6/parquet" # .parquet文件所在目录
csv_dir = "./output_csv/test6/csv" # .csv文件的生成存放目录
def clean_quote(value):
if isinstance(value, str):
value = value.strip().replace('""', '"').replace('"', '')
if ',' in value or '"' in value:
value = f'"{value}"'
return value
for file_name in os.listdir(parquet_dir):
if file_name.endswith('.parquet'):
parquet_file = os.path.join(parquet_dir, file_name)
csv_file = os.path.join(csv_dir, file_name.replace('.parquet', '.csv'))
df = pd.read_parquet(parquet_file)
for column in df.select_dtypes(include=['object']).columns:
df[column] = df[column].apply(clean_quote)
df.to_csv(csv_file, index=False, quoting=csv.QUOTE_NONNUMERIC)
print(f"Converted {parquet_file} to {csv_file} successfully.")
print("All Parquet files have been converted to CSV.") 将生成的csv文件复制到neo4j-community-5.23.0-windows/import目录下
开启neo4j服务并进入UI界面,在页面上方复制以下命令并运行命令:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144// 1. Import Documents
LOAD CSV WITH HEADERS FROM 'file:///create_final_documents.csv' AS row
CREATE (d:Document {
id: row.id,
title: row.title,
raw_content: row.raw_content,
text_unit_ids: row.text_unit_ids
});
// 2. Import Text Units
LOAD CSV WITH HEADERS FROM 'file:///create_final_text_units.csv' AS row
CREATE (t:TextUnit {
id: row.id,
text: row.text,
n_tokens: toFloat(row.n_tokens),
document_ids: row.document_ids,
entity_ids: row.entity_ids,
relationship_ids: row.relationship_ids
});
// 3. Import Entities
LOAD CSV WITH HEADERS FROM 'file:///create_final_entities.csv' AS row
CREATE (e:Entity{
id: row.id,
name: row.name,
type: row.type,
description: row.description,
human_readable_id: toInteger(row.human_readable_id),
text_unit_ids: row.text_unit_ids
});
// 4. Import Relationships
LOAD CSV WITH HEADERS FROM 'file:///create_final_relationships.csv' AS row
CREATE (r:Relationship {
source: row.source,
target: row.target,
weight: toFloat(row.weight),
description: row.description,
id: row.id,
human_readable_id: row.human_readable_id,
source_degree: toInteger(row.source_degree),
target_degree: toInteger(row.target_degree),
rank: toInteger(row.rank),
text_unit_ids: row.text_unit_ids
});
// 5. Import Nodes
LOAD CSV WITH HEADERS FROM 'file:///create_final_nodes.csv' AS row
CREATE (n:Node {
id: row.id,
level: toInteger(row.level),
title: row.title,
type: row.type,
description: row.description,
source_id: row.source_id,
community: row.community,
degree: toInteger(row.degree),
human_readable_id: row.human_readable_id,
size: toInteger(row.size),
entity_type: row.entity_type,
top_level_node_id: row.top_level_node_id,
x: toInteger(row.x),
y: toInteger(row.y)
});
// 6. Import Communities
LOAD CSV WITH HEADERS FROM 'file:///create_final_communities.csv' AS row
CREATE (c:Community {
id: row.id,
title: row.title,
level: toInteger(row.level),
raw_community: row.raw_community,
relationship_ids: row.relationship_ids,
text_unit_ids: row.text_unit_ids
});
// 7. Import Community Reports
LOAD CSV WITH HEADERS FROM 'file:///create_final_community_reports.csv' AS row
CREATE (cr:CommunityReport {
id: row.id,
community: row.community,
full_content: row.full_content,
level: toInteger(row.level),
rank: toFloat(row.rank),
title: row.title,
rank_explanation: row.rank_explanation,
summary: row.summary,
findings: row.findings,
full_content_json: row.full_content_json
});
// 8. Create indexes for better performance
CREATE INDEX FOR (d:Document) ON (d.id);
CREATE INDEX FOR (t:TextUnit) ON (t.id);
CREATE INDEX FOR (e:Entity) ON (e.id);
CREATE INDEX FOR (r:Relationship) ON (r.id);
CREATE INDEX FOR (n:Node) ON (n.id);
CREATE INDEX FOR (c:Community) ON (c.id);
CREATE INDEX FOR (cr:CommunityReport) ON (cr.id);
// 9. Create relationships after all nodes are imported
MATCH (d:Document)
UNWIND split(d.text_unit_ids, ',') AS textUnitId
MATCH (t:TextUnit {id: trim(textUnitId)})
CREATE (d)-[:HAS_TEXT_UNIT]->(t);
MATCH (t:TextUnit)
UNWIND split(t.entity_ids, ',') AS entityId
MATCH (e:Entity {id: trim(entityId)})
CREATE (t)-[:HAS_ENTITY]->(e);
MATCH (t:TextUnit)
UNWIND split(t.relationship_ids, ',') AS relId
MATCH (r:Relationship {id: trim(relId)})
CREATE (t)-[:HAS_RELATIONSHIP]->(r);
MATCH (e:Entity)
UNWIND split(e.text_unit_ids, ',') AS textUnitId
MATCH (t:TextUnit {id: trim(textUnitId)})
CREATE (e)-[:MENTIONED_IN]->(t);
MATCH (r:Relationship)
MATCH (source:Entity {name: r.source})
MATCH (target:Entity {name: r.target})
CREATE (source)-[:RELATES_TO]->(target);
MATCH (r:Relationship)
UNWIND split(r.text_unit_ids, ',') AS textUnitId
MATCH (t:TextUnit {id: trim(textUnitId)})
CREATE (r)-[:MENTIONED_IN]->(t);
MATCH (c:Community)
UNWIND split(c.relationship_ids, ',') AS relId
MATCH (r:Relationship {id: trim(relId)})
CREATE (c)-[:HAS_RELATIONSHIP]->(r);
MATCH (c:Community)
UNWIND split(c.text_unit_ids, ',') AS textUnitId
MATCH (t:TextUnit {id:trim(textUnitId)})
CREATE (c)-[:HAS_TEXT_UNIT]->(t);
MATCH (cr:CommunityReport)
MATCH (c:Community {id: cr.community})
CREATE (cr)-[:REPORTS_ON]->(c);最好在运行这段命令之前nei4j数据库没有其他的节点数据,最好是一次性完成。
如果出现报错,最简单的方法是重新解压原来的压缩包,重新开一个新的数据库,然后重复之前的操作
2.3 自行创建简单图谱示例
安装依赖库1
pip install py2neo
以下代码是一个简单的图谱生成示例:1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56import py2neo
from py2neo import Graph, Node, Relationship, NodeMatcher
g = Graph("neo4j://localhost:7687", user="neo4j", password="") # 填入自己的用户名和密码
g.run('match (n) detach delete n') # 运行neo4j自己的命令,删除所有节点
# 创建节点,指定标签并命名
testnode1 = Node("Person", name="刘备")
testnode2 = Node("Person", name="关羽")
testnode3 = Node("Person", name="张飞")
# 构建节点属性
# 也可以在创建时设置,如testnode1 = Node("Person", name="刘备", country="蜀国", age=40, sex="男")
testnode1['country'] = '蜀国'
testnode1['age'] = 40
testnode1['sex'] = '男'
testnode2['country'] = '蜀国'
testnode2['age'] = 35
testnode2['sex'] = '男'
testnode3['country'] = '蜀国'
testnode3['age'] = 30
testnode3['sex'] = '男'
# 无条件创建节点,必定会增加节点,不论是否与之前已有的节点重复
# g.create(testnode1)
# g.create(testnode2)
# g.create(testnode3)
# 覆盖式创建节点,根据给定条件进行覆盖创建
g.merge(testnode1, "People", "name")
g.merge(testnode2, "People", "name")
g.merge(testnode3, "People", "name")
# 构建关系
friend1 = Relationship(testnode1, "大哥", testnode2)
friend2 = Relationship(testnode2, "二弟", testnode1)
friend3 = Relationship(testnode1, "大哥", testnode3)
friend4 = Relationship(testnode3, "三弟", testnode1)
friend5 = Relationship(testnode2, "二哥", testnode3)
friend6 = Relationship(testnode3, "三弟", testnode2)
g.merge(friend1, "Person", "name")
g.merge(friend2, "Person", "name")
g.merge(friend3, "Person", "name")
g.merge(friend4, "Person", "name")
g.merge(friend5, "Person", "name")
g.merge(friend6, "Person", "name")
# 查询相关属性
matcher = NodeMatcher(g)
print(matcher.match("Person", name="张飞").first())
生成效果: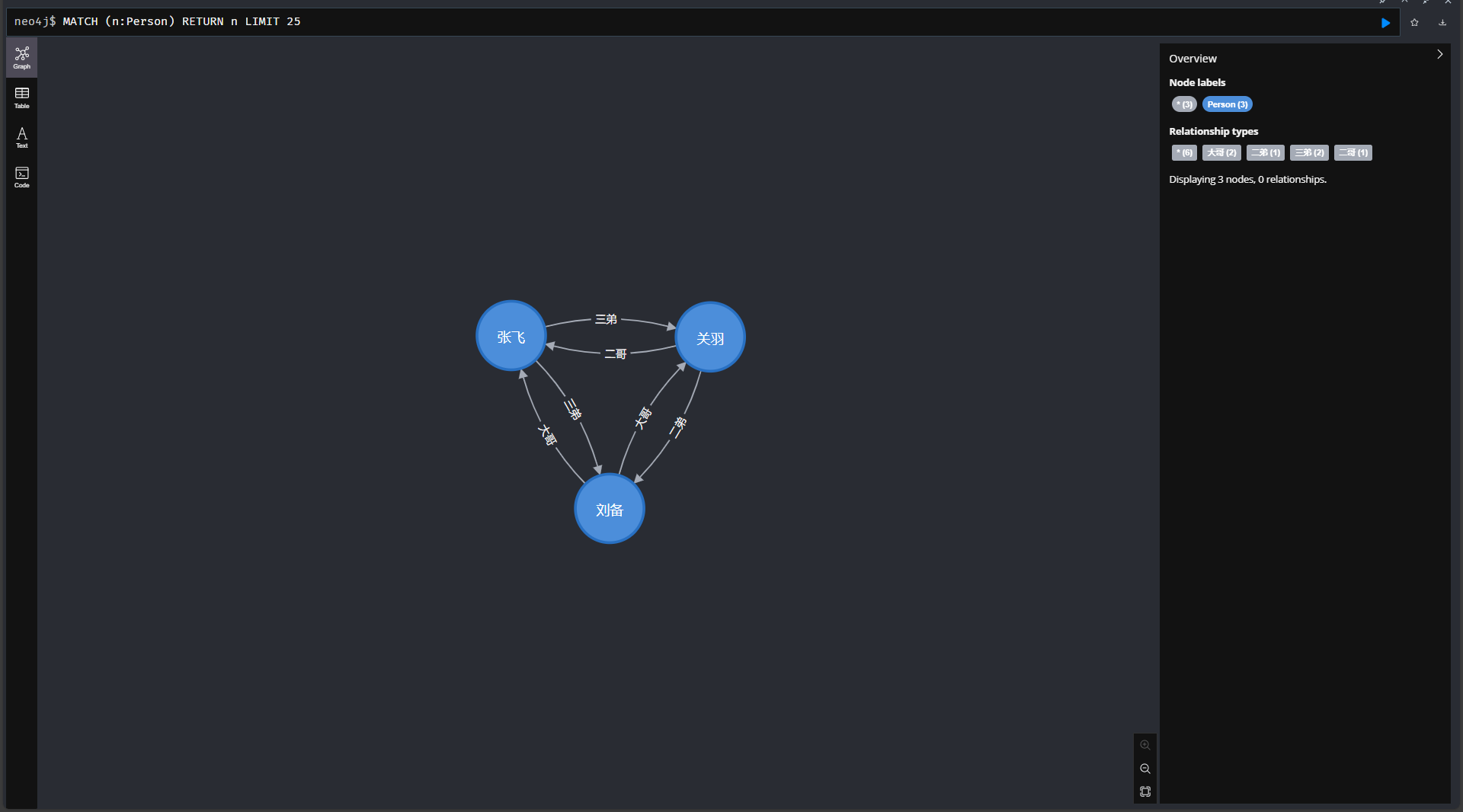
2.4 知识图谱构建案例分析
2.4.1 红楼梦人物关系图谱构建
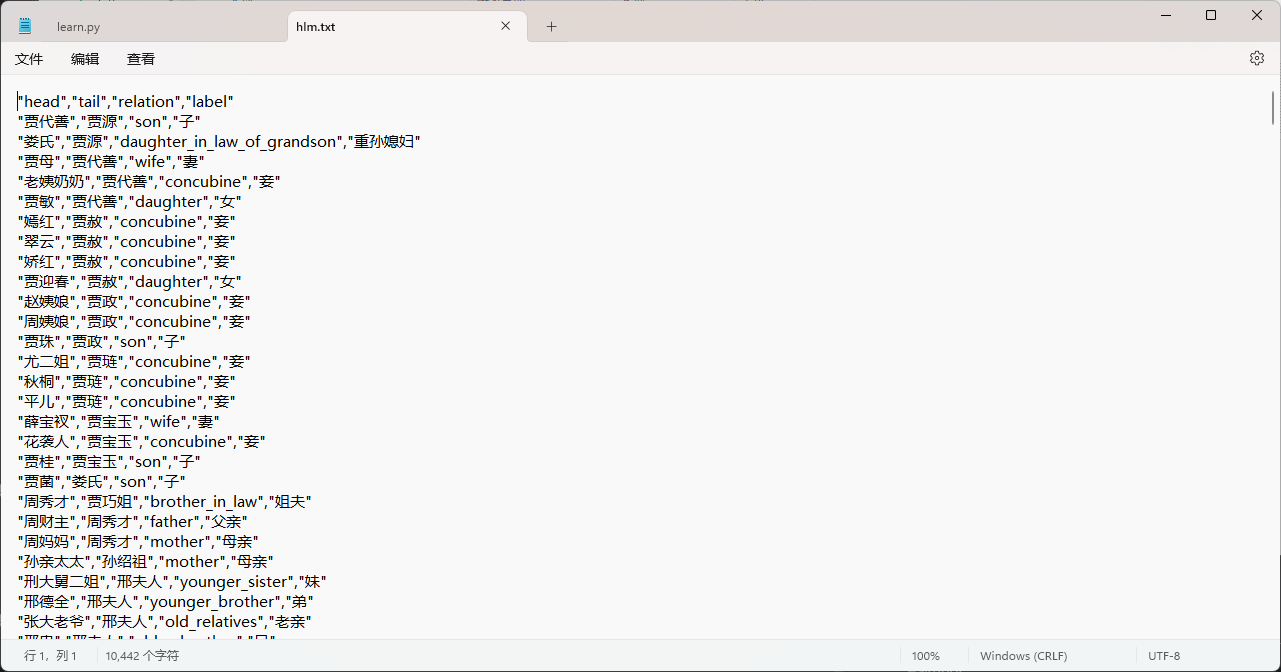
- 构建方法:通过已搜集好的人物关系表格构建知识图谱,表格样式如下:

表格中已经非常明确的给出了各节点之间的关系。 - 代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18import csv
from py2neo import Graph,Node,Relationship,NodeMatcher
#账号密码改为自己的即可
g=Graph('neo4j://localhost:7687',user='neo4j',password='')
g.run('match (n) detach delete n')
with open('hlm.txt','r',encoding='utf-8') as f:
reader=csv.reader(f)
for item in reader:
if reader.line_num==1:
continue
print("当前行数:",reader.line_num,"当前内容:",item)
start_node=Node("Person",name=item[0])
end_node=Node("Person",name=item[1])
relation=Relationship(start_node,item[3],end_node)
g.merge(start_node,"Person","name")
g.merge(end_node,"Person","name")
g.merge(relation,"Person","name")
print('end') - 优劣性说明
这种方法来得最直接,不过需要费时间搜集或者自己整理出相关的关系数据,整理出这样一份表格。2.4.2 借助AI大模型进行知识图谱构建
这种方法非常类似GraphRAG,直接将文本输给gpt,然后提出类似“请抽取其中的实体和实体间的关系,并生成neo4j代码”的要求,剩下的工作便可交给gpt完成。
GraphRAG只不过是让这一过程自动化进行,其中真正来处理文本,抽取实体等工作还是交给了大模型。2.4.3 医疗知识图谱构建
项目源地址
与红楼梦人物知识图谱构建所需的数据格式类似,需要整理好的数据
不同的是项目还提供了爬虫模块,支持从指定的网站上爬取信息,并对信息进行数据整理以达到可以进行图谱构建的目的。
项目还有问答功能,不用api接口实现。
- wechat
- alipay

